Model evaluation
CSI 4106 - Fall 2024
Version: Oct 11, 2024 10:39
Generating a nonlinear dataset

Linear regression

A linear model inadequately represents this dataset
Polynomial regression
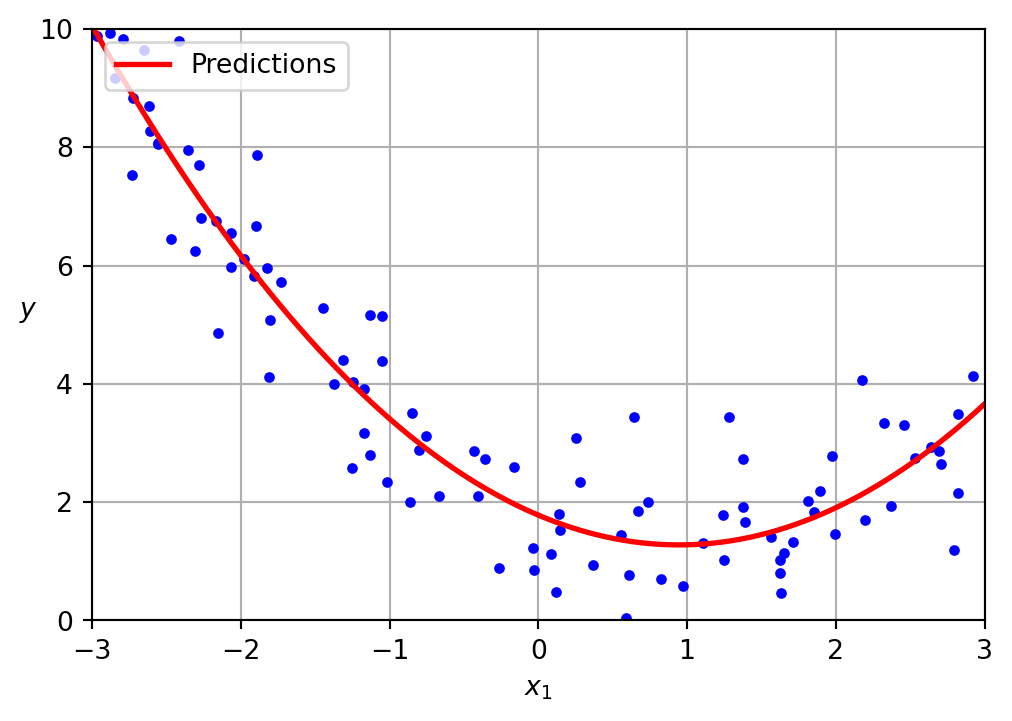
LinearRegression on PolynomialFeatures
Polynomial regression

The data was generated according to the following equation, with the inclusion of Gaussian noise.
\[ y = 0.5 x^2 + 1.0 x + 2.0 \]
Presented below is the learned model.
\[ \hat{y} = 0.56 x^2 + (-1.06) x + 1.78 \]
Overfitting and underfitting
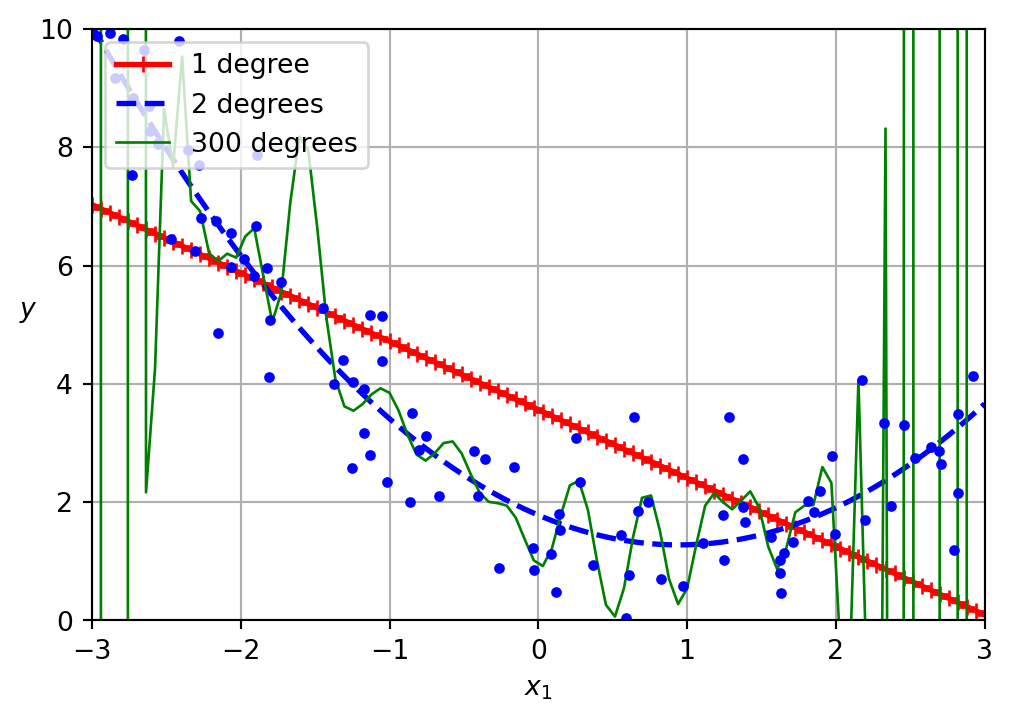
A low loss value on the training set does not necessarily indicate a “better” model.
Learning curve – underfitting
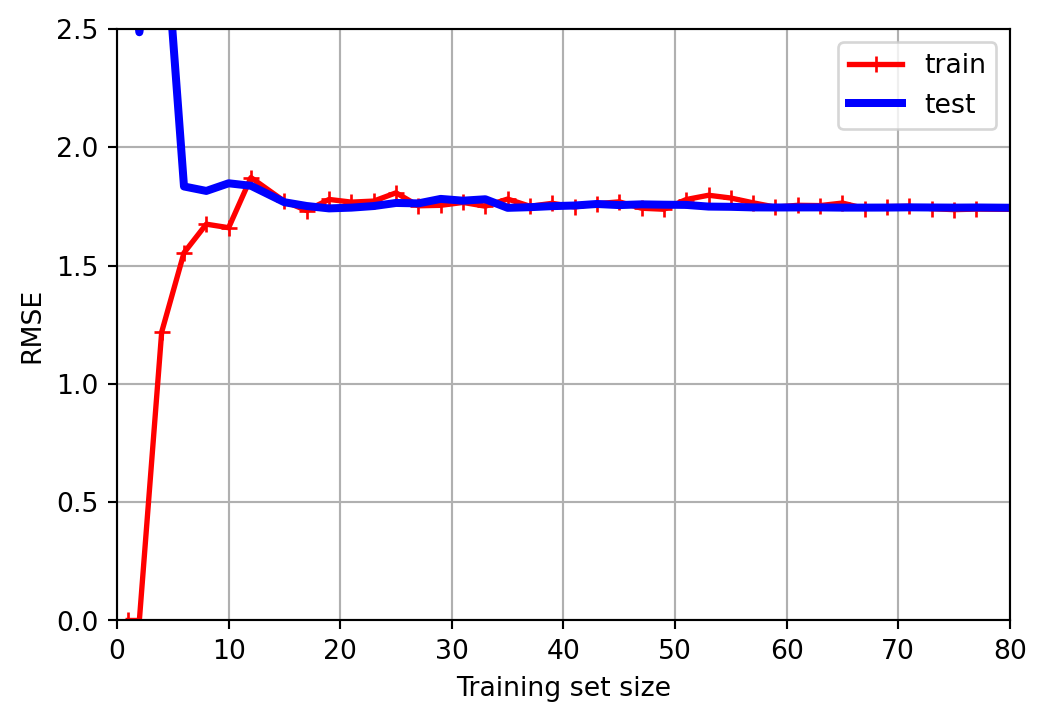
Poor performance on both training and test data.
Learning curve – overfitting

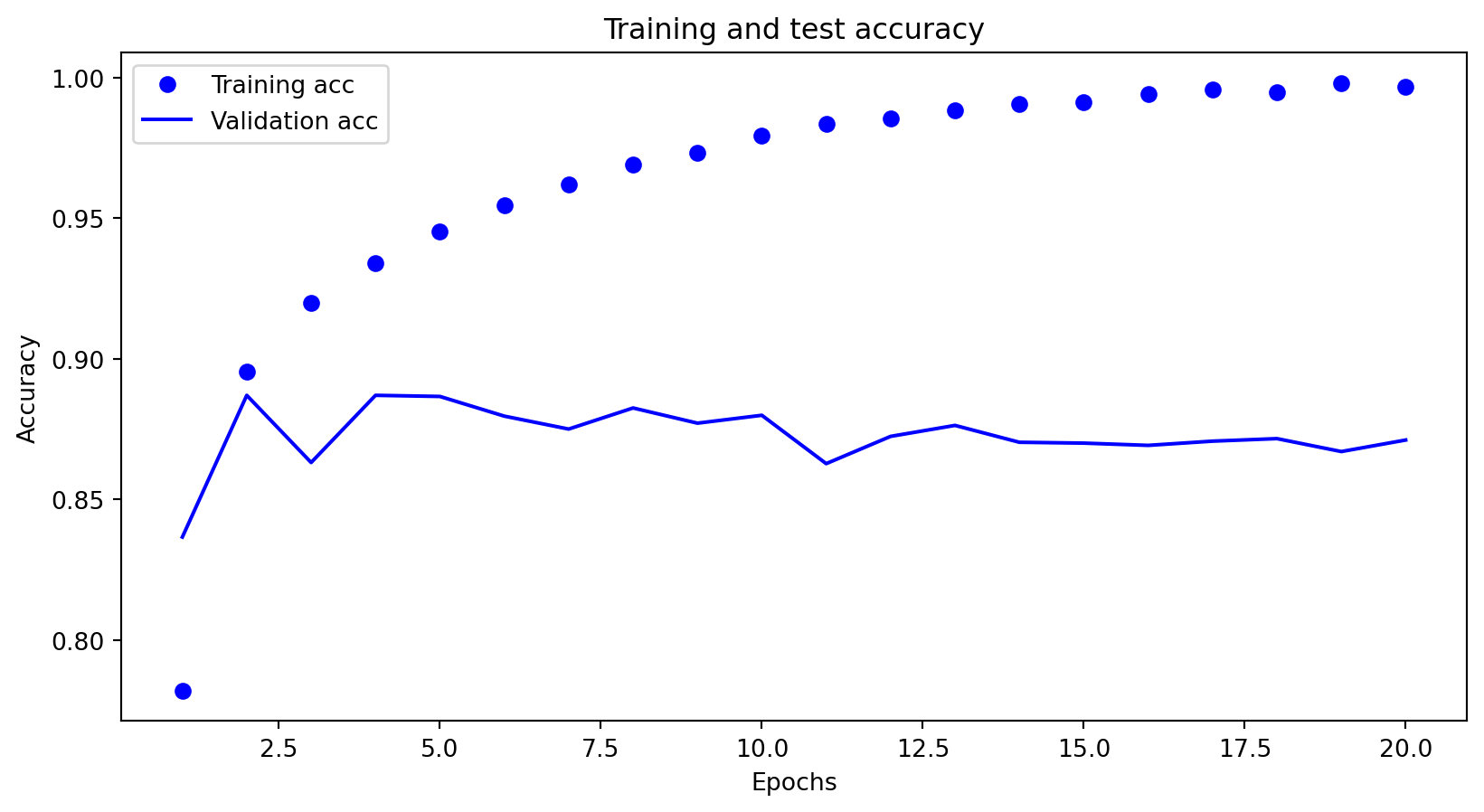
Excellent performance on the training set, but poor performance on the test set.
Overfitting - deep nets - loss

Overfitting - deep nets - accuracy
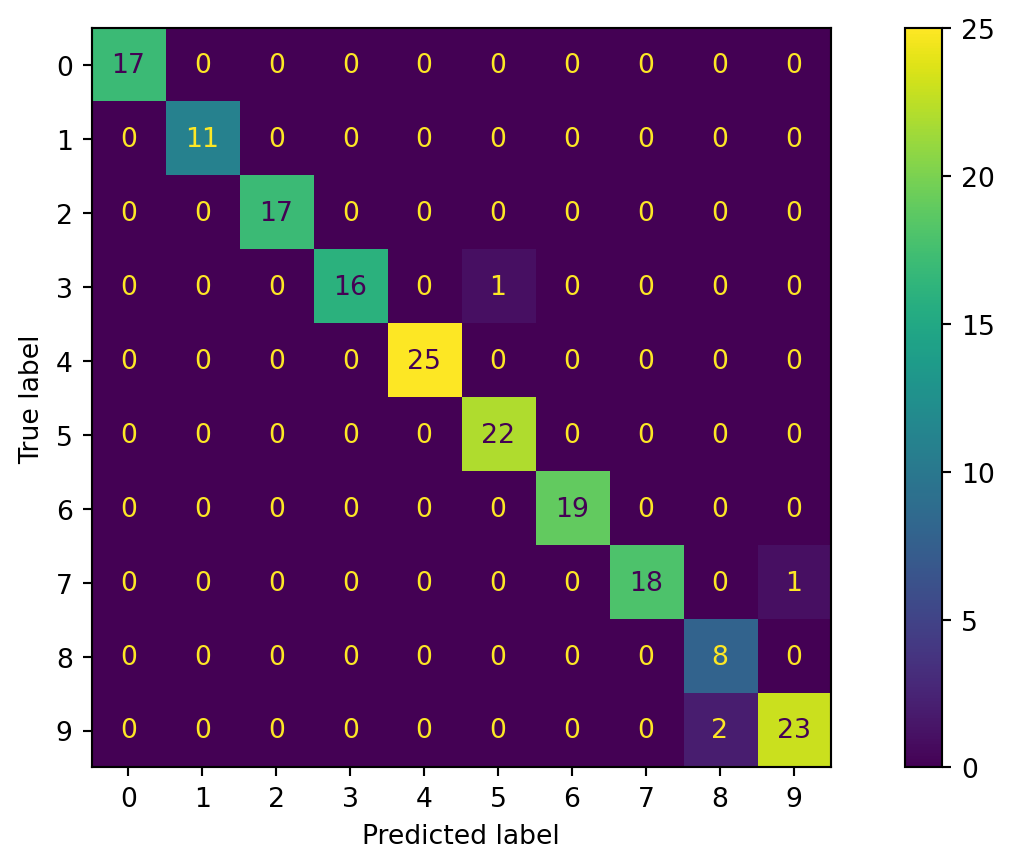
Confusion matrix - multiple classes

Visualizing errors

Confusion matrix - multiple classes
Micro/macro metrics
from sklearn.metrics import ConfusionMatrixDisplay
# Sample data
y_true = ['Cat'] * 42 + ['Dog'] * 7 + ['Fox'] * 11
y_pred = ['Cat'] * 39 + ['Dog'] * 1 + ['Fox'] * 2 + \
['Cat'] * 4 + ['Dog'] * 3 + ['Fox'] * 0 + \
['Cat'] * 5 + ['Dog'] * 1 + ['Fox'] * 5
ConfusionMatrixDisplay.from_predictions(y_true, y_pred)
Micro/macro recall

precision recall f1-score support
Cat 0.81 0.93 0.87 42
Dog 0.60 0.43 0.50 7
Fox 0.71 0.45 0.56 11
accuracy 0.78 60
macro avg 0.71 0.60 0.64 60
weighted avg 0.77 0.78 0.77 60
Micro recall: 0.78
Macro recall: 0.60Macro-average recall is calculated as the mean of the recall scores for each class: \(\frac{0.93 + 0.43 + 0.45}{3} = 0.60\).
Whereas, the micro-average recall is calculated using the formala, \(\frac{TP}{TP+FN}\) and the data from the entire confusion matrix \(\frac{39+3+5}{39+3+5+3+4+6} = \frac{39}{60} = 0.78\)
Micro/macro metrics (medical data)

Consider a medical dataset, such as those involving diagnostic tests or imaging, comprising 990 normal samples and 10 abnormal (tumor) samples. This represents the ground truth.
Hand-written digits (revisited)
Loading the dataset
Plotting the first five examples

These images have dimensions of ( 28 ) pixels.
Precision-recall trade-off
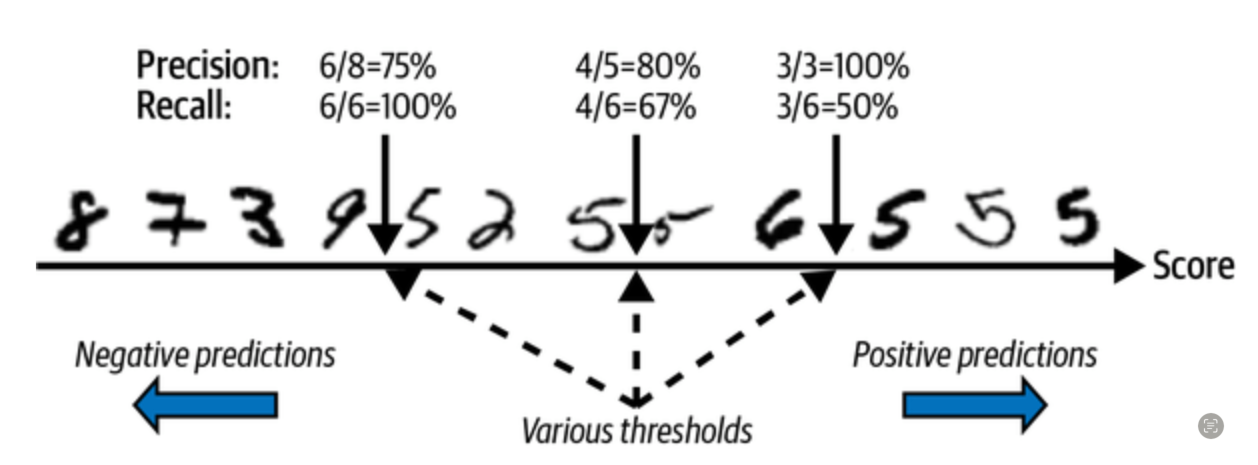
Precision-recall trade-off

Precision/Recall curve

ROC curve

AUC/ROC

Further reading

{kind=link}
Marcel Turcotte
School of Electrical Engineering and Computer Science (EECS)
University of Ottawa