
Modèles linéaires, entraînement
CSI 4506 - automne 2024
Marcel Turcotte
Version: sept. 30, 2024 08h54
Préamble
Citation du jour
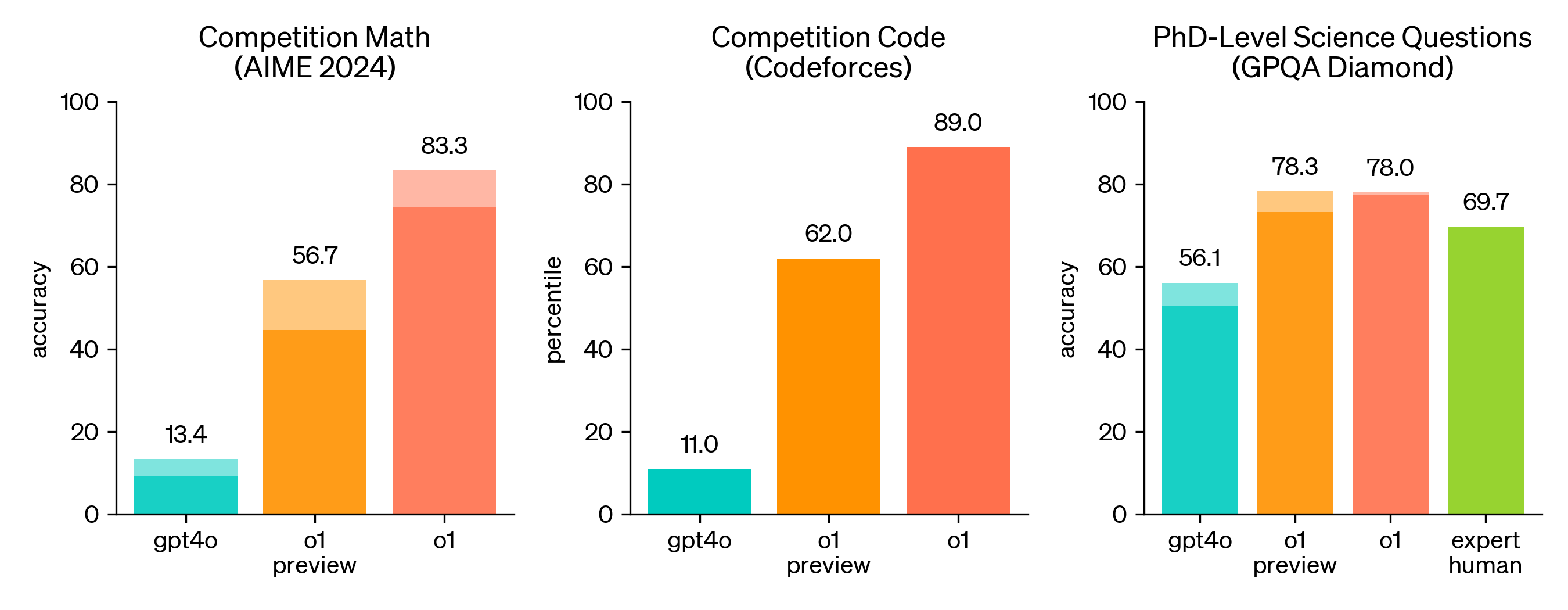
Citation du jour (suite)
Entraînement d’un modèle linéaire
Dans ce cours, nous couvrirons les concepts fondamentaux de la régression linéaire et de la descente de gradient.
Vous acquerrez une compréhension approfondie de ces techniques essentielles d’apprentissage automatique, vous permettant de les appliquer efficacement dans votre travail.
Objectif général
- Expliquer le processus d’entraînement d’un modèle linéaire
Objectifs d’apprentissage
- Distinguer entre les tâches de régression et de classification.
- Expliquer le processus d’entraînement des modèles de régression linéaire.
- Expliquer dans vos propres mots le rôle des algorithmes d’optimisation dans le contexte d’une régression linéaire.
- Décrire le rôle des dérivées partielles dans l’algorithme de descente de gradient.
- Comparer les algorithmes de descente de gradient batch, stochastique et mini-batch.
Lectures
- Basé sur Géron (2019), \(\S\) 4.
Problème
Apprentissage supervisé - régression
- Les données d’entraînement sont un ensemble d’exemples étiquetés.
- \(\{(x_i, y_i)\}_{i=1}^N\)
- Chaque \(x_i\) est un vecteur d’attributs avec \(D\) dimensions.
- \(x_i^{(j)}\) est la valeur de l’attribut \(j\) de l’exemple \(i\), pour \(j \in 1 \ldots D\) et \(i \in 1 \ldots N\).
- L’étiquette \(y_i\) est un nombre réel.
- \(\{(x_i, y_i)\}_{i=1}^N\)
- Problème : Étant donné l’ensemble de données en entrée, créer un modèle qui peut être utilisé pour prédire la valeur de \(y\) pour un \(x\) non vu.
k-plus-proches voisins
Justification
La régression linéaire est introduite pour présenter de manière pratique un algorithme d’entraînement bien connu, la descente de gradient. De plus, elle sert de base pour introduire la régression logistique—un algorithme de classification—qui facilite davantage les discussions sur les réseaux de neurones artificiels.
- Régression linéaire
- Descente de gradient
- Régression logistique
- Réseaux de neurones
Apprentissage supervisé - régression
Pouvez-vous penser à des exemples de tâches de régression ?
- Prédiction du Prix des Maisons :
- Application : Estimer la valeur marchande des propriétés résidentielles en fonction de caractéristiques telles que l’emplacement, la taille, le nombre de chambres, l’âge et les commodités.
- Prévision du Marché Boursier :
- Application : Prédire les prix futurs des actions ou des indices basés sur des données historiques, des indicateurs financiers et des variables économiques.
- Prédiction Météorologique :
- Application : Estimer les températures futures, les précipitations et autres conditions météorologiques en utilisant des données météorologiques historiques et des variables atmosphériques.
- Prévision des Ventes :
- Application : Prédire les volumes de ventes futurs pour des produits ou services en analysant les données de ventes passées, les tendances du marché et les modèles saisonniers.
- Prédiction de la Consommation d’Énergie :
- Application : Prévoir la consommation future d’énergie pour les ménages, les industries ou les villes en se basant sur des données de consommation historiques, les conditions météorologiques et les facteurs économiques.
- Estimation des Coûts Médicaux :
- Application : Prédire les coûts des soins de santé pour les patients en fonction de leur historique médical, des informations démographiques et des plans de traitement.
- Prédiction du Flux de Trafic :
- Application : Estimer les volumes de trafic futurs et les niveaux de congestion sur les routes et autoroutes en utilisant des données historiques de trafic et des entrées de capteurs en temps réel.
- Estimation de la Valeur à Vie du Client (CLV) :
- Application : Prédire le revenu total qu’une entreprise peut attendre d’un client sur la durée de leur relation, en se basant sur le comportement d’achat et les données démographiques.
- Prévision des Indicateurs Économiques :
- Application : Prédire les indicateurs économiques clés tels que la croissance du PIB, les taux de chômage et l’inflation en utilisant des données économiques historiques et les tendances du marché.
- Prévision de la Demande :
- Application : Estimer la demande future de produits ou services dans diverses industries comme le commerce de détail, la fabrication et la logistique pour optimiser la gestion des stocks et de la chaîne d’approvisionnement.
- Évaluation Immobilière :
- Application : Évaluer la valeur marchande des propriétés commerciales telles que les immeubles de bureaux, les centres commerciaux et les espaces industriels en fonction de l’emplacement, de la taille et des conditions du marché.
- Évaluation des Risques d’Assurance :
- Application : Prédire le risque associé à l’assurance des individus ou des propriétés, ce qui aide à déterminer les taux de prime, en se basant sur les données historiques de sinistres et les facteurs démographiques.
- Prédiction du Taux de Clics sur les Publicités (CTR) :
- Application : Estimer la probabilité qu’un utilisateur clique sur une publicité en ligne en fonction du comportement de l’utilisateur, des caractéristiques de la publicité et des facteurs contextuels.
- Prédiction du Risque de Défaut de Prêt :
- Application : Prédire la probabilité qu’un emprunteur fasse défaut sur un prêt en fonction de l’historique de crédit, du revenu, du montant du prêt et d’autres indicateurs financiers.
Apprentissage supervisé - régression
En se concentrant sur des applications pouvant fonctionner sur un appareil mobile.
- Prédiction de l’Autonomie de la Batterie :
- Application : Estimer l’autonomie restante de la batterie en fonction des habitudes d’utilisation, des applications en cours d’exécution et des paramètres de l’appareil.
- Suivi de la Santé et de la Condition Physique :
- Application : Prédire la dépense calorique, la fréquence cardiaque ou la qualité du sommeil en fonction de l’activité de l’utilisateur, des données biométriques et des données de santé historiques.
- Gestion des Finances Personnelles :
- Application : Prévoir les dépenses ou économies futures en fonction des habitudes de dépense, des modèles de revenu et des objectifs budgétaires.
- Prévision Météorologique :
- Application : Fournir des prévisions météorologiques personnalisées en fonction de la localisation actuelle et des données météorologiques historiques.
- Estimation du Temps de Trajet et du Trafic :
- Application : Prédire les temps de trajet et suggérer des itinéraires optimaux en fonction des données de trafic historiques, des conditions en temps réel et du comportement de l’utilisateur.
- Amélioration de la Qualité des Images et Vidéos :
- Application : Ajuster les paramètres de qualité des images ou vidéos (par exemple, luminosité, contraste) en fonction des conditions d’éclairage et des préférences de l’utilisateur.
- Atteinte des Objectifs de Condition Physique :
- Application : Estimer le temps nécessaire pour atteindre des objectifs de condition physique tels que la perte de poids ou le gain musculaire en fonction de l’activité de l’utilisateur et des apports alimentaires.
- Optimisation des Performances des Appareils Mobiles :
- Application : Prédire les paramètres optimaux pour les performances de l’appareil et la durée de vie de la batterie en fonction des habitudes d’utilisation et de l’activité des applications.
Régression linéaire
- Un modèle linéaire suppose que la valeur de l’étiquette, \(\hat{y_i}\), peut être exprimée comme une combinaison linéaire des valeurs des attributs, \(x_i^{(j)}\) : \[ \hat{y_i} = h(x_i) = \theta_0 + \theta_1 x_i^{(1)} + \theta_2 x_i^{(2)} + \ldots + \theta_D x_i^{(D)} \]
- Ici, \(\theta_{j}\) est le \(j\)-ième paramètre du modèle (linéaire), avec \(\theta_0\) étant le terme/le paramètre de biais, et \(\theta_1 \ldots \theta_D\) étant les poids des attributs.
Régression Linéaire (suite)
Problème : trouver des valeurs pour tous les paramètres du modèle afin que le modèle s’ajuste au mieux aux données d’entraînement.
- L’erreur quadratique moyenne (root mean square error (RMSE)) est une mesure de performance courante pour les problèmes de régression.
\[ \sqrt{\frac{1}{N}\sum_1^N [h(x_i) - y_i]^2} \]
Régression linéaire
Code source
Interactions GPT 4o (2024-09-14)
Utilisateur : Expliquez le code sur l’écran précédent ligne par ligne.
IA : Certainement ! Voici une explication ligne par ligne du code fourni :
- Explication : Cette ligne importe la bibliothèque NumPy, qui est un paquet fondamental pour les calculs numériques en Python. Elle est couramment utilisée pour travailler avec des tableaux et des matrices, ainsi que pour effectuer diverses opérations mathématiques.
- Explication : Cette ligne génère un tableau NumPy
Xcontenant 100 lignes et 1 colonne de nombres aléatoires. La fonctionnp.random.rand(100, 1)génère des nombres aléatoires uniformément distribués entre 0 et 1. La multiplication par 6 ajuste ces nombres à la plage [0, 6), et la soustraction de 4 déplace la plage à [-4, 2).
Explication : Cette ligne génère la variable cible
ybasée sur une équation quadratique avec du bruit ajouté. Plus précisément :X ** 2calcule le carré de chaque élément deX.- 4 * Xsoustrait quatre fois chaque élément deX.+ 5ajoute une constante de 5.+ np.random.randn(100, 1)ajoute du bruit gaussien avec une moyenne de 0 et un écart-type de 1 à chaque élément, rendant les données plus réalistes en introduisant une certaine variabilité.
- Explication : Cette ligne importe la classe
LinearRegressiondu modulesklearn.linear_model, qui fait partie de la bibliothèque Scikit-Learn. Scikit-Learn est largement utilisée pour l’apprentissage automatique en Python.
- Explication : Cette ligne crée une instance de la classe
LinearRegressionet l’assigne à la variablelin_reg. Cet objet sera utilisé pour ajuster le modèle de régression linéaire aux données.
- Explication : Cette ligne ajuste le modèle de régression linéaire aux données en trouvant la meilleure ligne passant par les points
(X, y). La méthodefitentraîne le modèle en utilisant les caractéristiques fourniesXet la variable cibley.
- Explication : Cette ligne crée un nouveau tableau NumPy
X_newavec deux valeurs : -4 et 2. Ces valeurs représentent de nouveaux points de données pour lesquels nous voulons prédire la variable cible en utilisant le modèle entraîné.
- Explication : Cette ligne utilise le modèle de régression linéaire entraîné pour prédire la variable cible
y_predpour les nouveaux points de données dansX_new. La méthodepredictrenvoie les valeurs prédites basées sur le modèle ajusté.
En résumé, ce script génère des données synthétiques, ajuste un modèle de régression linéaire à ces données, puis utilise le modèle pour faire des prédictions sur de nouveaux points de données.
Source code (continued)
import os
import matplotlib as mpl
import matplotlib.pyplot as plt
def save_fig(fig_id, tight_layout=True, fig_extension="pdf", resolution=300):
path = os.path.join(fig_id + "." + fig_extension)
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)Source code (continued)
Andrew Ng

- Gradient Descent (Math)
(11:30 m) - Intuition
(11:51 m) - Linear Regression
(10:20 m) - ML-005 | Stanford | Andrew Ng
(19 videos)
Mathématiques
3Blue1Brown
- Essence de l’algèbre linéaire
- Une série de 16 vidéos (10 à 15 minutes par vidéo) offrant “une compréhension géométrique des matrices, déterminants, valeurs propres et plus encore.”
- 6 662 732 vues au 30 septembre 2019.
- Une série de 16 vidéos (10 à 15 minutes par vidéo) offrant “une compréhension géométrique des matrices, déterminants, valeurs propres et plus encore.”
- Essence du calcul
- Une série de 12 vidéos (15 à 20 minutes par vidéo) : “L’objectif ici est de faire en sorte que le calcul apparaisse comme quelque chose que vous auriez pu découvrir vous-même.”
- 2 309 726 vues au 30 septembre 2019.
- Une série de 12 vidéos (15 à 20 minutes par vidéo) : “L’objectif ici est de faire en sorte que le calcul apparaisse comme quelque chose que vous auriez pu découvrir vous-même.”
Problème (prise 2)
Apprentissage supervisé - régression
- Les données d’entraînement sont un ensemble d’exemples étiquetés.
- \(\{(x_i, y_i)\}_{i=1}^N\)
- Chaque \(x_i\) est un vecteur d’attributs avec \(D\) dimensions.
- \(x_i^{(j)}\) est la valeur de l’attribut \(j\) de l’exemple \(i\), pour \(j \in 1 \ldots D\) et \(i \in 1 \ldots N\).
- L’étiquette \(y_i\) est un nombre réel.
- \(\{(x_i, y_i)\}_{i=1}^N\)
- Problème : Étant donné l’ensemble de données en entrée, créer un modèle qui peut être utilisé pour prédire la valeur de \(y\) pour un \(x\) non vu.
Composants fondamentaux
Composants fondamentaux
Un algorithme d’apprentissage typique comprend les composants suivants :
Un modèle, souvent constitué d’un ensemble de poids dont les valeurs seront “apprises”.
Une fonction objectif.
- Dans le cas de la régression, il s’agit souvent d’une fonction de perte, (loss function) une fonction qui quantifie les erreurs de classification. L’erreur quadratique moyenne (root mean square error (RMSE)) est une fonction de perte courante pour les problèmes de régression. \[ \sqrt{\frac{1}{N}\sum_1^N [h(x_i) - y_i]^2} \]
Un algorithme d’optimisation
Optimisation
Jusqu’à ce que certains critères d’arrêt soient atteints\(^1\) :
Évaluer la fonction de perte, en comparant \(h(x_i)\) à \(y_i\).
Apporter de petites modifications aux poids, de manière à réduire la valeur de la fonction de perte.
1: Par exemple, la valeur de la fonction de perte ne diminue plus ou le nombre maximal d’itérations est atteint.
Dérivée

- Nous commencerons par une fonction à une variable.
- Considérez cela comme notre fonction de perte, que nous visons à minimiser; pour réduire la disparité moyenne entre les valeurs attendues et les valeurs prédites.
- J’utilise le symbol \(t\) pour la variable afin d’éviter toute confusion avec les attributs des exemples de notre jeu de données.
Code source
Dérivée

Le graphe de la dérivée, \(f^{'}(t)\), est représenté en rouge.
La dérivée indique comment les changements dans l’entrée affectent la sortie, \(f(t)\).
La magnitude de la dérivée en \(t = -2\) est \(0\).
Ce point correspond au minimum de notre fonction.
Dérivée

Lorsqu’elle est évaluée en un point spécifique, la dérivée indique la pente de la ligne tangente au graphe de la fonction à ce point.
À \(t= -2\), la pente de la ligne tangente est de 0.
Dérivée

Une dérivée positive indique qu’augmenter la variable d’entrée entraînera une augmentation de la valeur de sortie.
De plus, la magnitude de la dérivée quantifie la rapidité du changement de la sortie.
Dérivée

Une dérivée négative indique qu’augmenter la variable d’entrée entraînera une diminution de la valeur de sortie.
De plus, la magnitude de la dérivée quantifie la rapidité du changement de la sortie.
Code source
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
# Define the variable and function
t = sp.symbols('t')
f = t**2 + 4*t + 7
# Compute the derivative
f_prime = sp.diff(f, t)
# Lambdify the functions for numerical plotting
f_func = sp.lambdify(t, f, "numpy")
f_prime_func = sp.lambdify(t, f_prime, "numpy")
# Generate t values for plotting
t_vals = np.linspace(-5, 2, 400)
# Get y values for the function and its derivative
f_vals = f_func(t_vals)
f_prime_vals = f_prime_func(t_vals)
# Plot the function and its derivative
plt.plot(t_vals, f_vals, label=r'$f(t) = t^2 + 4t + 7$', color='blue')
plt.plot(t_vals, f_prime_vals, label=r"$f'(t) = 2t + 4$", color='red')
# Fill the area below the derivative where it's negative
plt.fill_between(t_vals, f_prime_vals, where=(f_prime_vals > 0), color='red', alpha=0.3)
# Add labels and legend
plt.axhline(0, color='black',linewidth=1)
plt.axvline(0, color='black',linewidth=1)
plt.title('Function and Derivative')
plt.tlabel('t')
plt.ylabel('y')
plt.legend()
# Show the plot
plt.grid(True)
plt.show()Rappel
- Un modèle linéaire suppose que la valeur de l’étiquette, \(\hat{y_i}\), peut être exprimée comme une combinaison linéaire des valeurs des attributs, \(x_i^{(j)}\) : \[ \hat{y_i} = h(x_i) = \theta_0 + \theta_1 x_i^{(1)} + \theta_2 x_i^{(2)} + \ldots + \theta_D x_i^{(D)} \]
- Ici, \(\theta_{j}\) est le \(j\)ème paramètre du modèle (linéaire), avec \(\theta_0\) étant le terme/paramètre de biais, et \(\theta_1 \ldots \theta_D\) étant les poids des attributs.
Rappel
- L’erreur quadratique moyenne racine (RMSE) est une fonction de perte courante pour les problèmes de régression. \[ \sqrt{\frac{1}{N}\sum_1^N [h(x_i) - y_i]^2} \]
- En pratique, minimiser l’erreur quadratique moyenne (MSE) est plus facile et donne le même résultat. \[ \frac{1}{N}\sum_1^N [h(x_i) - y_i]^2 \]
Descente de gradient - intuition
Descente de gradient - une variable
- Notre modèle : \[ h(x_i) = \theta_0 + \theta_1 x_i^{(1)} \]
- Notre fonction de perte : \[ J(\theta_0, \theta_1) = \frac{1}{N}\sum_1^N [h(x_i) - y_i]^2 \]
- Problème : trouver les valeurs de \(\theta_0\) et \(\theta_1\) qui minimisent \(J\).
Descente de gradient - une variable
- Initialisation : \(\theta_0\) et \(\theta_1\) - soit avec des valeurs aléatoires, soit avec des zéros.
- Boucle :
- répéter jusqu’à convergence : \[ \theta_j := \theta_j - \alpha \frac {\partial}{\partial \theta_j}J(\theta_0, \theta_1) , \text{pour } j=0 \text{ et } j=1 \]
- \(\alpha\) est appelé le taux d’apprentissage - c’est la taille de chaque pas.
- \(\frac {\partial}{\partial \theta_j}J(\theta_0, \theta_1)\) est la dérivée partielle par rapport à \(\theta_j\).
Dérivées partielles
Étant donnée
\[ J(\theta_0, \theta_1) = \frac{1}{N}\sum_1^N [h(x_i) - y_i]^2 = \frac{1}{N}\sum_1^N [\theta_0 + \theta_1 x_i - y_i]^2 \]
Nous avons
\[ \frac {\partial}{\partial \theta_0}J(\theta_0, \theta_1) = \frac{2}{N} \sum\limits_{i=1}^{N} (\theta_0 - \theta_1 x_i - y_{i}) \]
et
\[ \frac {\partial}{\partial \theta_1}J(\theta_0, \theta_1) = \frac{2}{N} \sum\limits_{i=1}^{N} x_{i} \left(\theta_0 + \theta_1 x_i - y_{i}\right) \]
Dérivée partielle (SymPy)
from IPython.display import Math, display
from sympy import *
# Define the symbols
theta_0, theta_1, x_i, y_i = symbols('theta_0 theta_1 x_i y_i')
# Define the hypothesis function:
h = theta_0 + theta_1 * x_i
print("Hypothesis function:")
display(Math('h(x) = ' + latex(h)))Hypothesis function:\(\displaystyle h(x) = \theta_{0} + \theta_{1} x_{i}\)
Dérivée partielle (SymPy)
Dérivée partielle (SymPy)
# Calculate the partial derivative with respect to theta_0
partial_derivative_theta_0 = diff(J, theta_0)
print("Partial derivative with respect to theta_0:")
display(Math(latex(partial_derivative_theta_0)))Partial derivative with respect to theta_0:\(\displaystyle \frac{\sum_{x_{i}=1}^{N} \left(2 \theta_{0} + 2 \theta_{1} x_{i} - 2 y_{i}\right)}{N}\)
Dérivée partielle (SymPy)
# Calculate the partial derivative with respect to theta_1
partial_derivative_theta_1 = diff(J, theta_1)
print("Partial derivative with respect to theta_1:")
display(Math(latex(partial_derivative_theta_1)))Partial derivative with respect to theta_1:\(\displaystyle \frac{\sum_{x_{i}=1}^{N} 2 x_{i} \left(\theta_{0} + \theta_{1} x_{i} - y_{i}\right)}{N}\)
Régression linéaire multivariée
\[ h(x_i) = \theta_0 + \theta_1 x_i^{(1)} + \theta_2 x_i^{(2)} + \theta_3 x_i^{(3)} + \cdots + \theta_D x_i^{(D)} \]
\[ \begin{align*} x_i^{(j)} &= \text{valeur de l'attribut } j \text{ dans le } i \text{ème exemple} \\ D &= \text{le nombre d'attributs'} \end{align*} \]
Descente de gradient - multivariée
La nouvelle fonction de perte est
\[ J(\theta_0, \theta_1, \ldots, \theta_D) = \dfrac {1}{N} \displaystyle \sum _{i=1}^N \left( h(x_{i}) - y_i \right)^2 \]
Sa dérivée partielle :
\[ \frac {\partial}{\partial \theta_j}J(\theta) = \frac{2}{N} \sum\limits_{i=1}^N x_i^{(j)} \left( \theta x_i - y_i \right) \]
où \(\theta\), \(x_i\) et \(y_i\) sont des vecteurs, et \(\theta x_i\) est une opération vectorielle !
Vecteur gradient
Le vecteur contenant la dérivée partielle de \(J\) (par rapport à \(\theta_j\), pour \(j \in \{0, 1 \ldots D\}\)) est appelé le vecteur gradient.
\[ \nabla_\theta J(\theta) = \begin{pmatrix} \frac {\partial}{\partial \theta_0}J(\theta) \\ \frac {\partial}{\partial \theta_1}J(\theta) \\ \vdots \\ \frac {\partial}{\partial \theta_D}J(\theta)\\ \end{pmatrix} \]
- Ce vecteur donne la direction de la plus forte pente ascendante.
- Il donne son nom à l’algorithme de descente de gradient :
\[ \theta' = \theta - \alpha \nabla_\theta J(\theta) \]
Descente de gradient - multivariée
L’algorithme de descente de gradient devient :
Répétez jusqu’à convergence :
\[ \begin{aligned} \{ & \\ \theta_j := & \theta_j - \alpha \frac {\partial}{\partial \theta_j}J(\theta_0, \theta_1, \ldots, \theta_D) \\ & \text{pour } j \in [0, \ldots, D] \textbf{ (mettre à jour simultanément)} \\ \} & \end{aligned} \]
Descente de gradient - multivariée
Répétez jusqu’à convergence :
\[ \begin{aligned} \; \{ & \\ \; & \theta_0 := \theta_0 - \alpha \frac{2}{N} \sum\limits_{i=1}^{N} x^{0}_i(h(x_i) - y_i) \\ \; & \theta_1 := \theta_1 - \alpha \frac{2}{N} \sum\limits_{i=1}^{N} x^{1}_i(h(x_i) - y_i) \\ \; & \theta_2 := \theta_2 - \alpha \frac{2}{N} \sum\limits_{i=1}^{N} x^{2}_i(h(x_i) - y_i) \\ & \cdots \\ \} & \end{aligned} \]
Hypothèses
Quelles étaient nos hypothèses ?
- La fonction (objectif/de perte) est différentiable.
Local vs global
Une fonction est convexe si pour toute paire de points sur le graphe de la fonction, la ligne reliant ces deux points se trouve au-dessus ou sur le graphe.
Une fonction convexe possède un unique minimum.
La fonction de perte pour la régression linéaire (MSE) est convexe.
Pour les fonctions qui ne sont pas convexes, l’algorithme de descente de gradient converge vers un minimum local.
Les fonctions de perte généralement utilisées avec les régressions linéaires ou logistiques, et les Support Vector Machines (SVM) sont convexes, mais pas celles pour les réseaux de neurones artificiels.
Local vs global

Taux d’apprentissage

- Petits pas, des valeurs faibles pour \(\alpha\), feront que l’algorithme convergera lentement.
- Grands pas pourraient faire diverger l’algorithme.
- Remarquez comment l’algorithme ralentit naturellement en approchant d’un minimum.
Descente de gradient par lot (batch)
- Pour être plus précis, cet algorithme est connu sous le nom de descente de gradient par lot car à chaque itération, il traite le “lot entier” d’exemples d’apprentissage.
- La littérature suggère que l’algorithme pourrait mettre plus de temps à converger si les attributs sont sur des échelles différentes.
Descente de gradient par lot - inconvénient
- L’algorithme de descente de gradient par lot devient très lent à mesure que le nombre d’exemples d’apprentissage augmente.
- Cela est dû au fait que toutes les données d’apprentissage sont vues à chaque itération. L’algorithme est généralement exécuté pour un nombre fixe d’itérations, disons 1000.
Descente de gradient stochastique
L’algorithme de descente de gradient stochastique sélectionne aléatoirement un exemple d’apprentissage pour calculer son gradient.
epochs = 10
for epoch in range(epochs):
for i in range(N):
selection = np.random.randint(N)
# Calculate the gradient using selection
# Update the weights- Cela lui permet de fonctionner avec de grands ensembles d’apprentissage.
- Sa trajectoire n’est pas aussi régulière que l’algorithme par lot.
- En raison de sa trajectoire accidentée, il est souvent meilleur pour trouver les minima globaux par rapport à l’algorithme par lot.
- Sa trajectoire accidentée le fait rebondir autour des minima locaux.
Descente de gradient par mini-lots
- À chaque étape, plutôt que de sélectionner un exemple d’apprentissage comme le fait la SGD, la descente de gradient par mini-lots (mini-batch) sélectionne aléatoirement un petit nombre d’exemples d’apprentissage pour calculer les gradients.
- Sa trajectoire est plus régulière comparée à la SGD.
- À mesure que la taille des mini-lots augmente, l’algorithme devient de plus en plus similaire à la descente de gradient par lot, qui utilise tous les exemples à chaque étape.
- Il peut profiter de l’accélération matérielle des opérations matricielles, en particulier avec les GPU.
Résumé
La descente de gradient par lot est intrinsèquement lente et impraticable pour de grands ensembles de données nécessitant une prise en charge hors mémoire, bien qu’elle soit capable de gérer un nombre substantiel de caractéristiques.
La descente de gradient stochastique est rapide et bien adaptée pour traiter un grand volume d’exemples de manière efficace.
La descente de gradient par mini-lots combine les avantages des méthodes par lot et stochastiques ; elle est rapide, capable de gérer de grands ensembles de données, et tire parti de l’accélération matérielle, en particulier avec les GPU.
Optimisation et réseaux profonds
Nous allons brièvement revisiter le sujet en discutant des réseaux de neurones artificiels profonds, pour lesquels il existe des algorithmes d’optimisation spécialisés.
- Optimisation par Momentum
- Gradient Acceleré de Nesterov
- AdaGrad
- RMSProp
- Adam et Nadam
Dernier mot
- L’optimisation est un sujet vaste. D’autres algorithmes existent et sont utilisés dans d’autres contextes.
- Parmi eux :
- L’optimisation par essaims particulaires (PSO), les algorithmes génétiques (GA), et les algorithmes de colonie d’abeilles artificielles (ABC).
Régression linéaire - résumé
Un modèle linéaire suppose que la valeur de l’étiquette, \(\hat{y_i}\), peut être exprimée comme une combinaison linéaire des valeurs des caractéristiques, \(x_i^{(j)}\) : \[ \hat{y_i} = h(x_i) = \theta_0 + \theta_1 x_i^{(1)} + \theta_2 x_i^{(2)} + \ldots + \theta_D x_i^{(D)} \]
L’écart moyen quadratique (MSE) est : \[ \frac{1}{N}\sum_1^N [h(x_i) - y_i]^2 \]
La descente de gradient par lot, stochastique, ou par mini-lots peut être utilisée pour trouver les valeurs “optimales” des poids, \(\theta_j\) pour \(j \in 0, 1, \ldots, D\).
Le résultat est un régresseur, une fonction qui peut être utilisée pour prédire la valeur \(y\) (l’étiquette) pour un exemple non vu \(x\).
Prologue
References
Géron, Aurélien. 2019. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 2nd éd. O’Reilly Media.
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.
Stanton, Jeffrey M. 2001. « Galton, Pearson, and the Peas: A Brief History of Linear Regression for Statistics Instructors ». Journal of Statistics Education 9 (3). https://doi.org/10.1080/10691898.2001.11910537.
Prochain cours
- Évaluation des modèles d’apprentissage automatique
Marcel Turcotte
École de science informatique et de génie électrique (SIGE)
Université d’Ottawa
