Évaluation des modèles
CSI 4506 - Automne 2024
Version: sept. 30, 2024 08h54
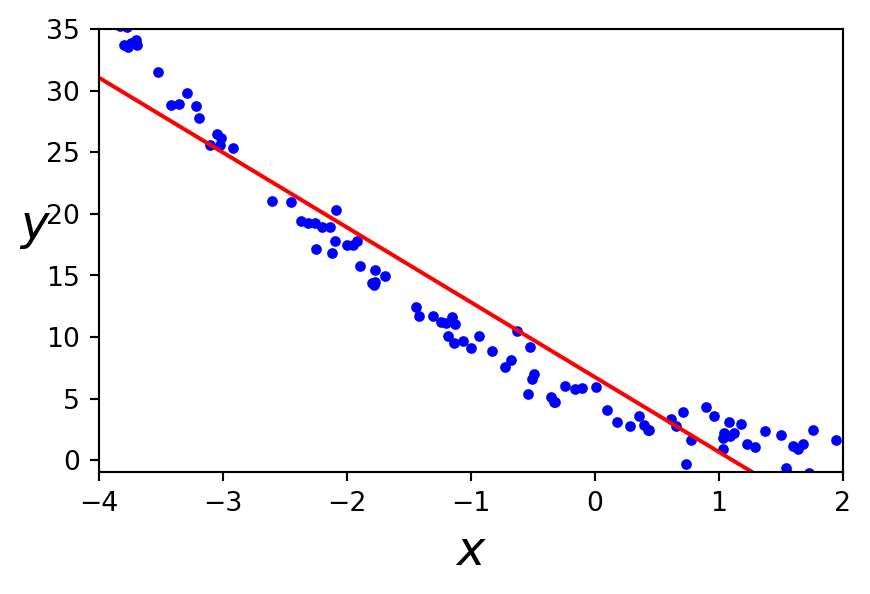
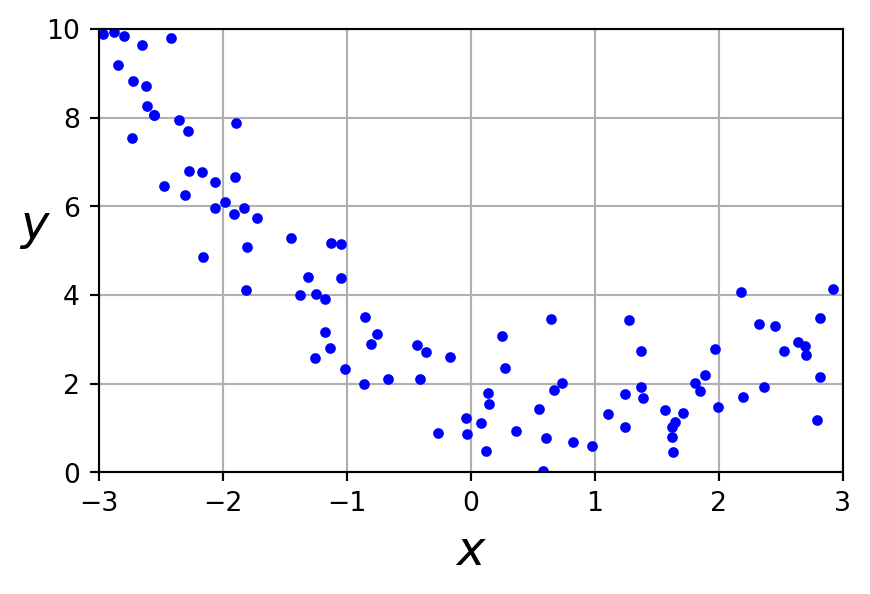
Un ensemble de données non linéaire
Régression linéaire
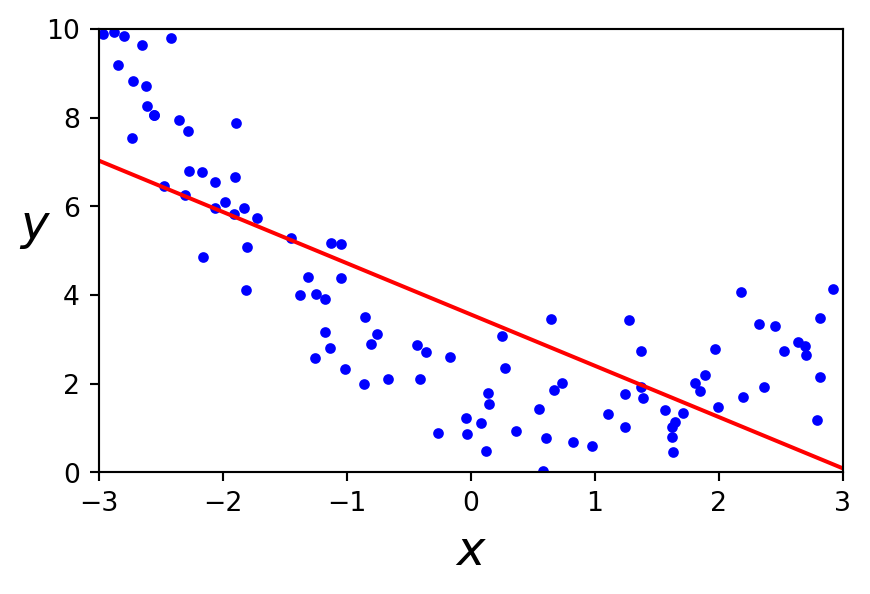
Un modèle linéaire représente mal ce jeu de données
Régression polynomiale
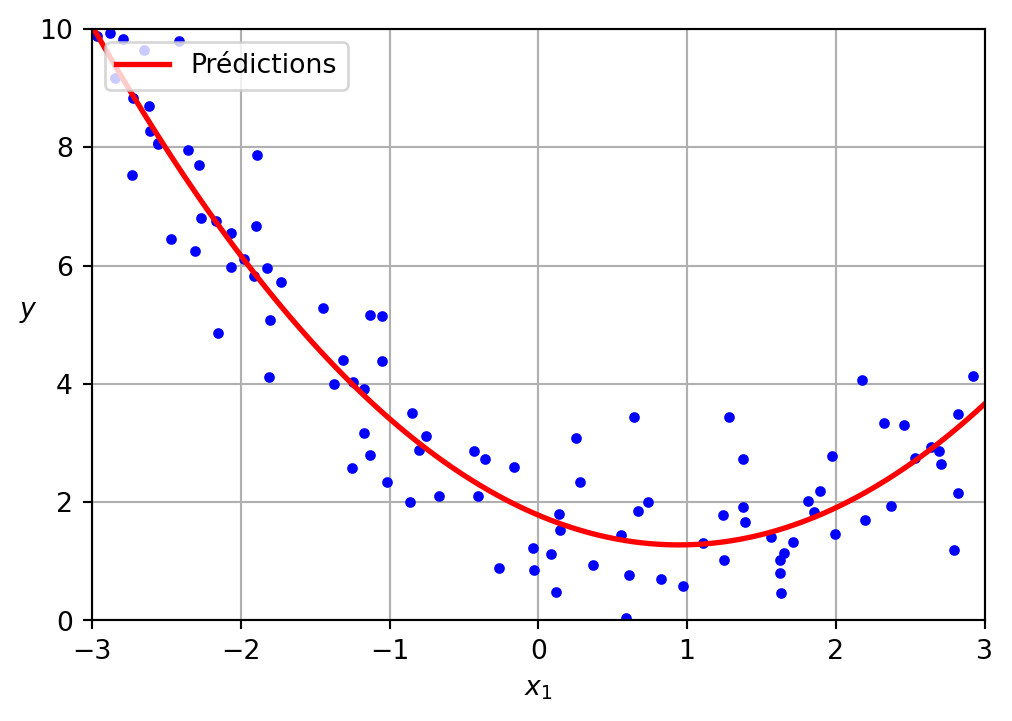
LinearRegression sur PolynomialFeatures
Régression polynomiale
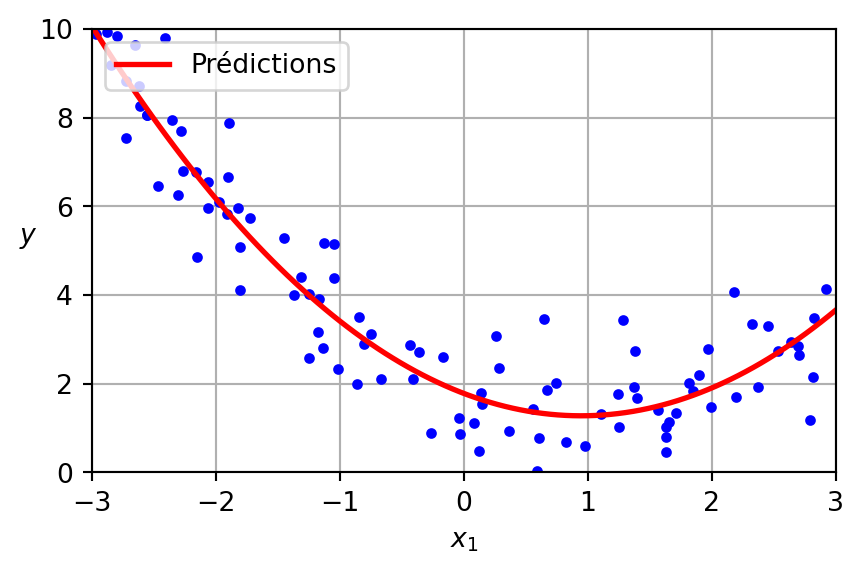
Les données ont été générées selon l’équation suivante, avec l’inclusion de bruit gaussien.
\[ y = 0.5 x^2 + 1.0 x + 2.0 \]
Le modèle appris est présenté ci-dessous.
\[ \hat{y} = 0.56 x^2 + (-1.06) x + 1.78 \]
Surapprentissage et sous-apprentissage
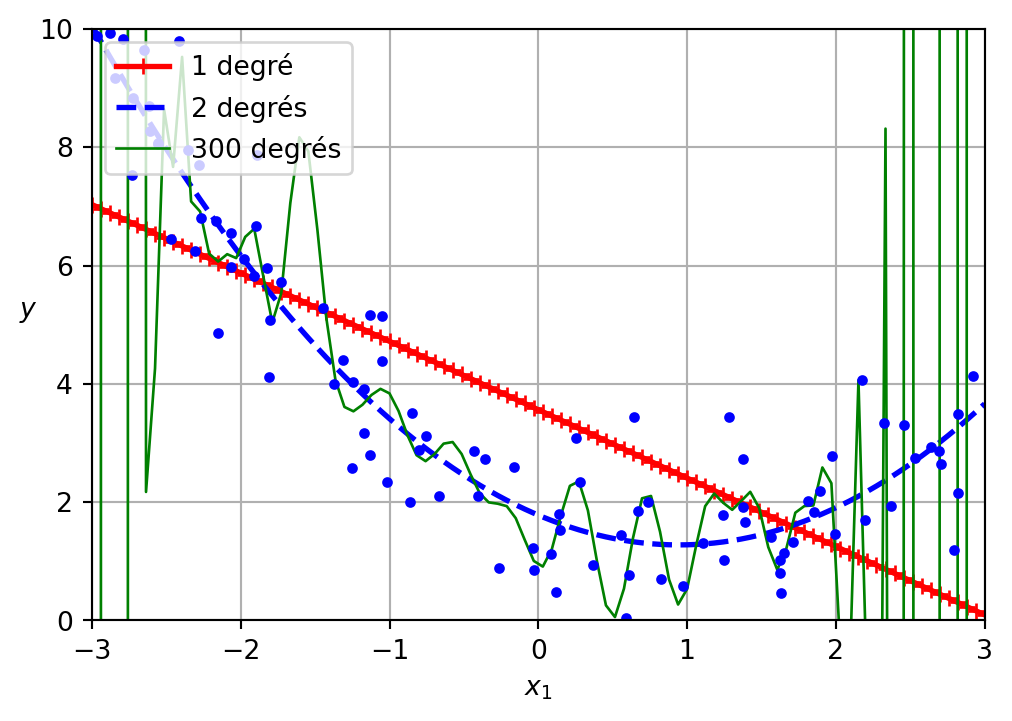
Une faible valeur de perte sur l’ensemble d’entraînement n’indique pas nécessairement un “meilleur” modèle.
Sous-apprentissage
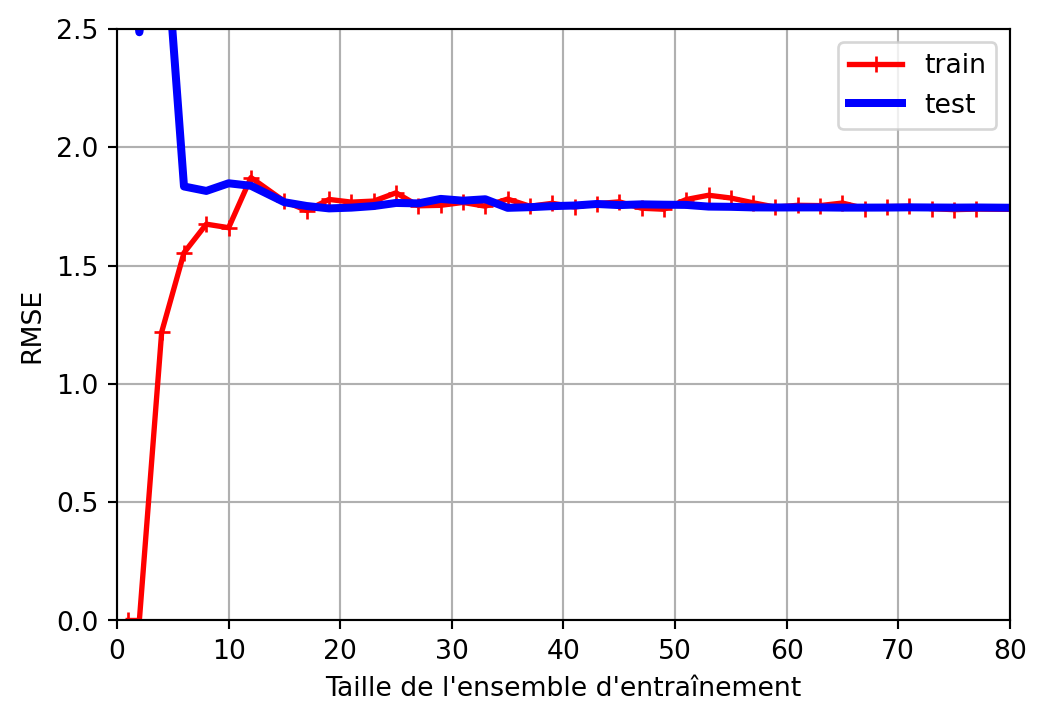
Mauvaise performance à la fois sur les données d’entraînement et les données de test.
Surapprentissage
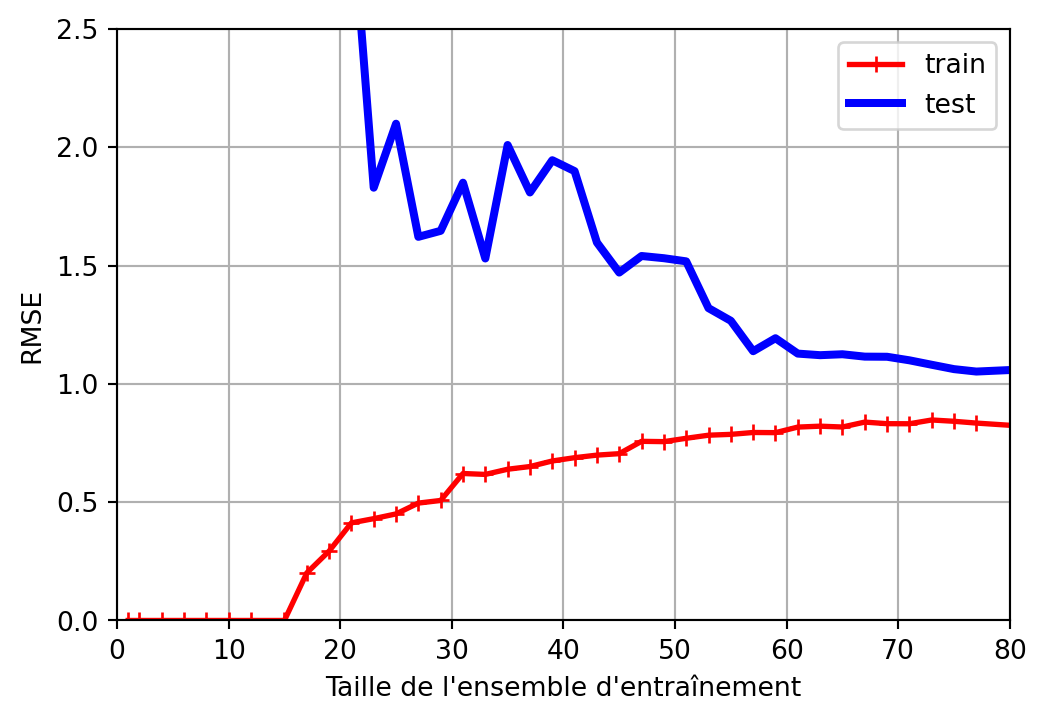
Excellentes performances sur l’ensemble d’entraînement, mais mauvaises performances sur l’ensemble de test.
Surapprentissage - réseaux profonds
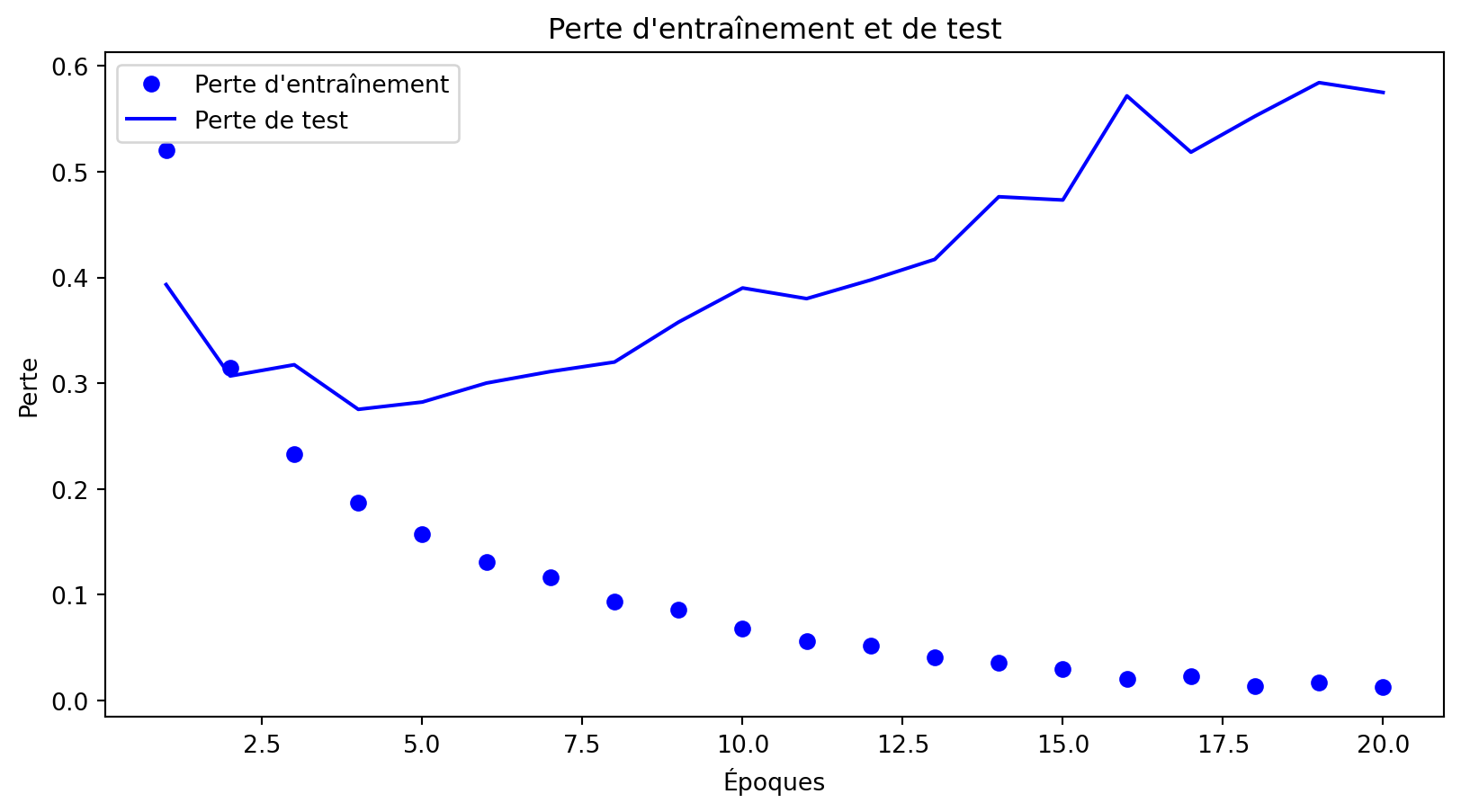
Surapprentissage - réseaux profonds

Matrice de confusion - plusieurs classes
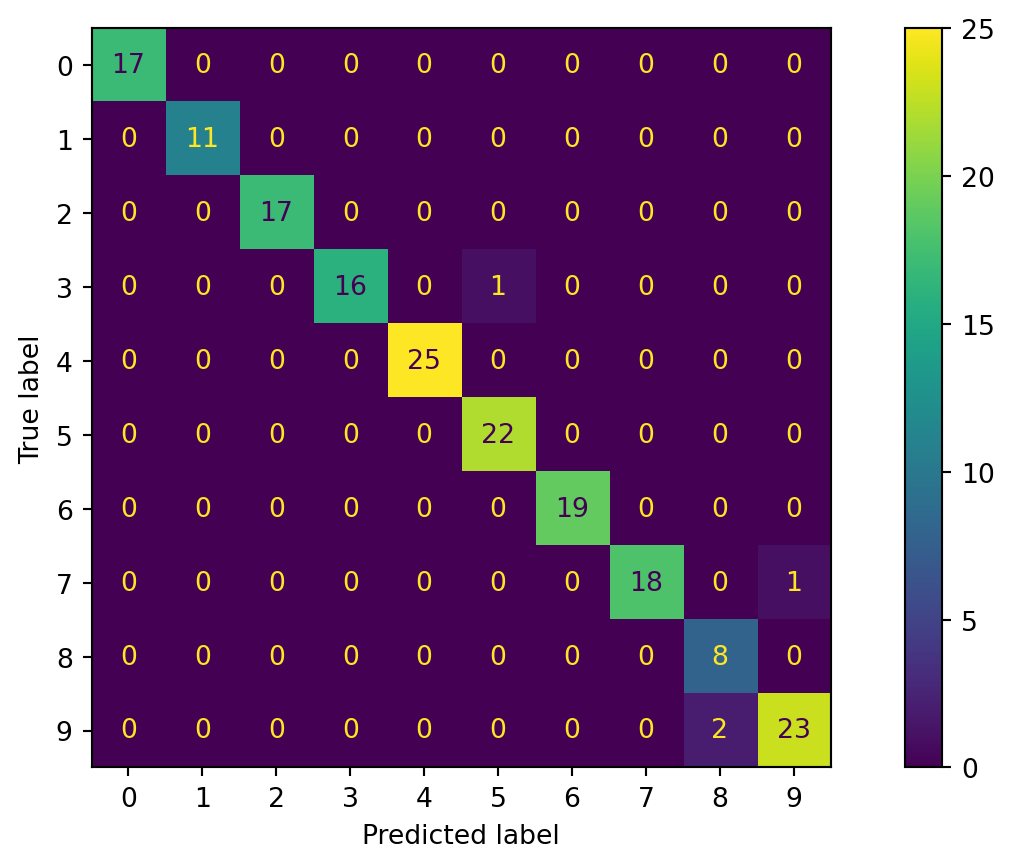
Visualisation des erreurs
Matrice de confusion - plusieurs classes
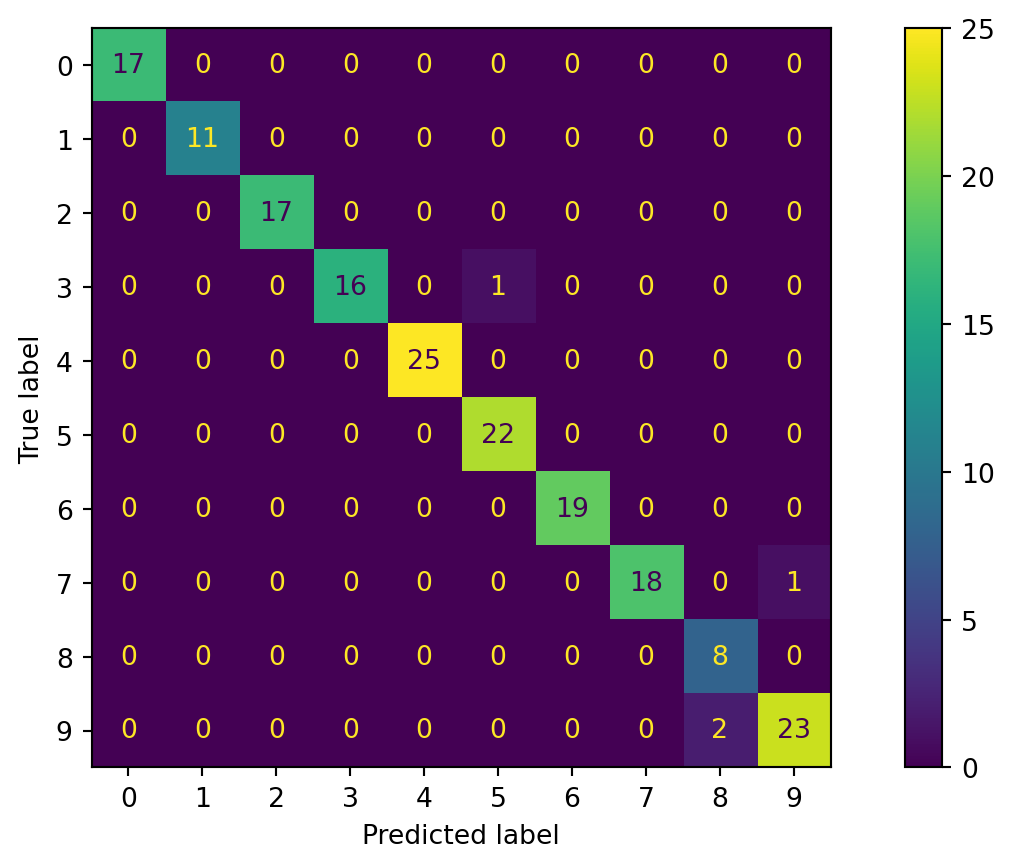
Précision micro/macro
from sklearn.metrics import ConfusionMatrixDisplay
# Données d'exemple
y_true = ['Chat'] * 42 + ['Chien'] * 7 + ['Renard'] * 11
y_pred = ['Chat'] * 39 + ['Chien'] * 1 + ['Renard'] * 2 + \
['Chat'] * 4 + ['Chien'] * 3 + ['Renard'] * 0 + \
['Chat'] * 5 + ['Chien'] * 1 + ['Renard'] * 5
ConfusionMatrixDisplay.from_predictions(y_true, y_pred)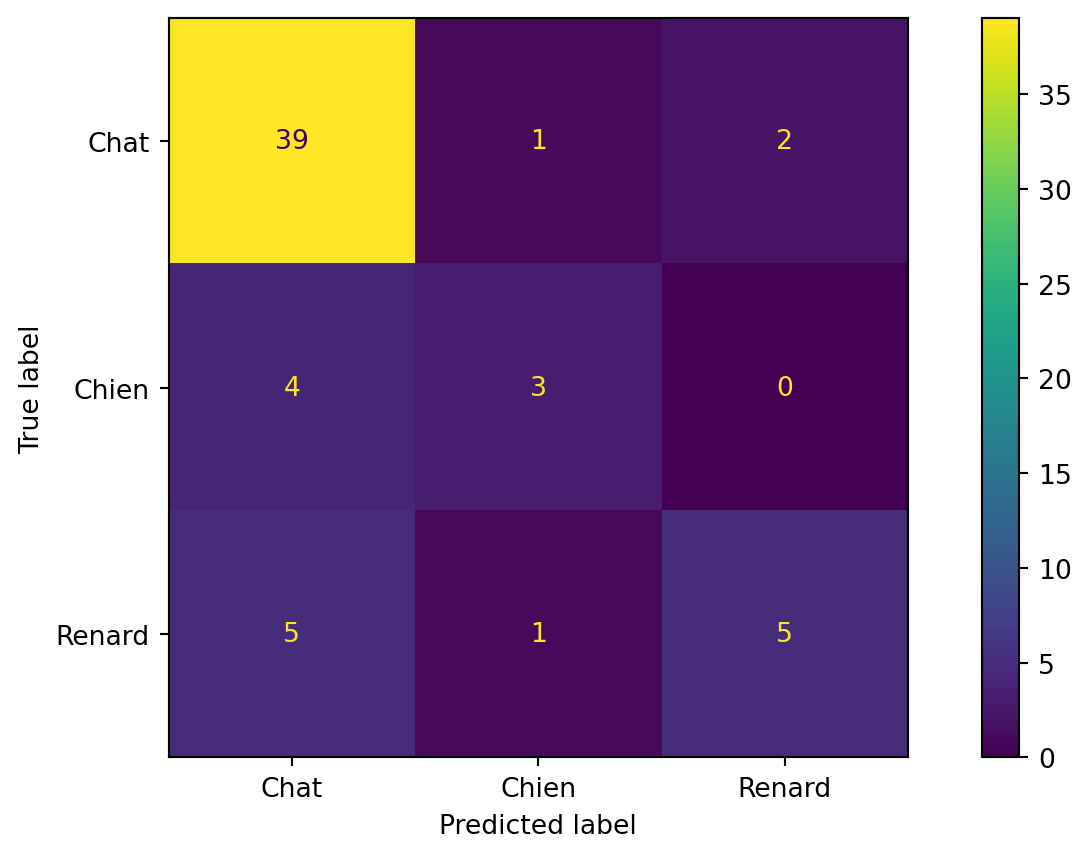
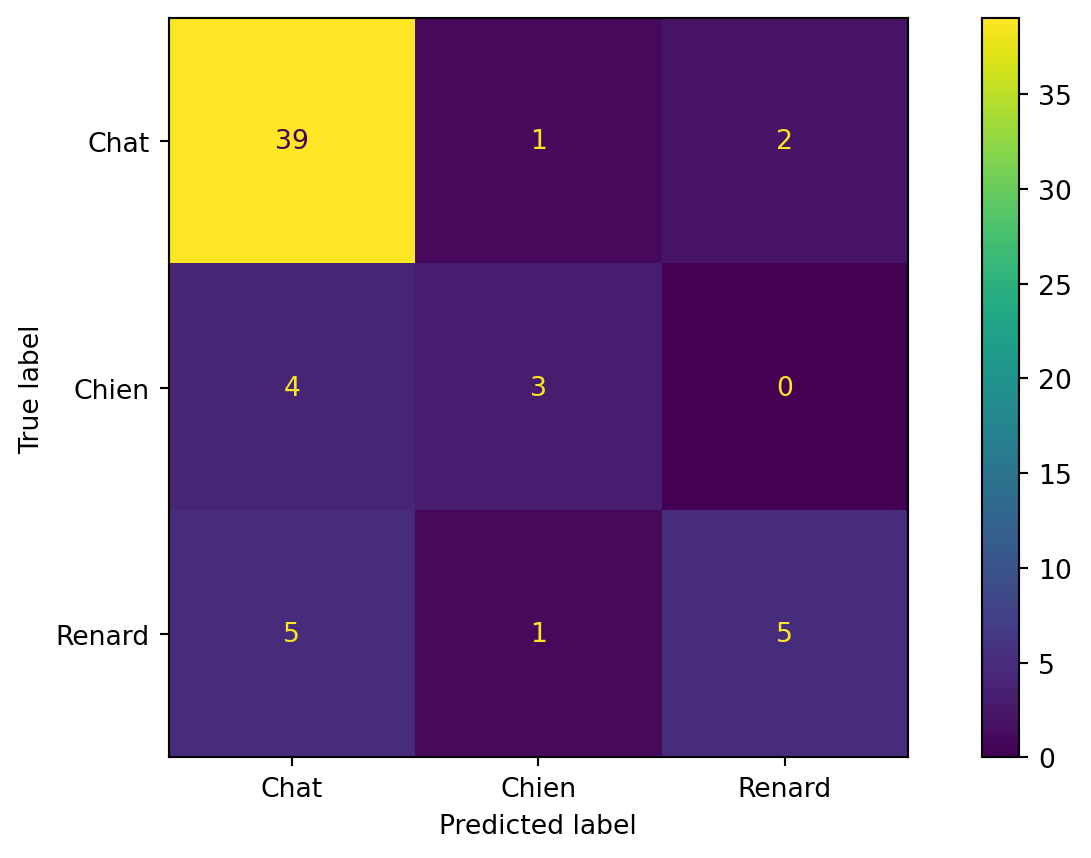
Rappel micro/macro
precision recall f1-score support
Chat 0.81 0.93 0.87 42
Chien 0.60 0.43 0.50 7
Renard 0.71 0.45 0.56 11
accuracy 0.78 60
macro avg 0.71 0.60 0.64 60
weighted avg 0.77 0.78 0.77 60
Rappel micro : 0.78
Rappel macro : 0.60Le rappel macro-moyen est calculé comme la moyenne des scores de rappel pour chaque classe : \(\frac{0.93 + 0.43 + 0.45}{3} = 0.60\).
Alors que le rappel micro-moyen est calculé en utilisant la formule \(\frac{VP}{VP+FN}\) et les données provenant de toute la matrice de confusion \(\frac{39+3+5}{39+3+5+3+4+6} = \frac{47}{60} = 0.78\)
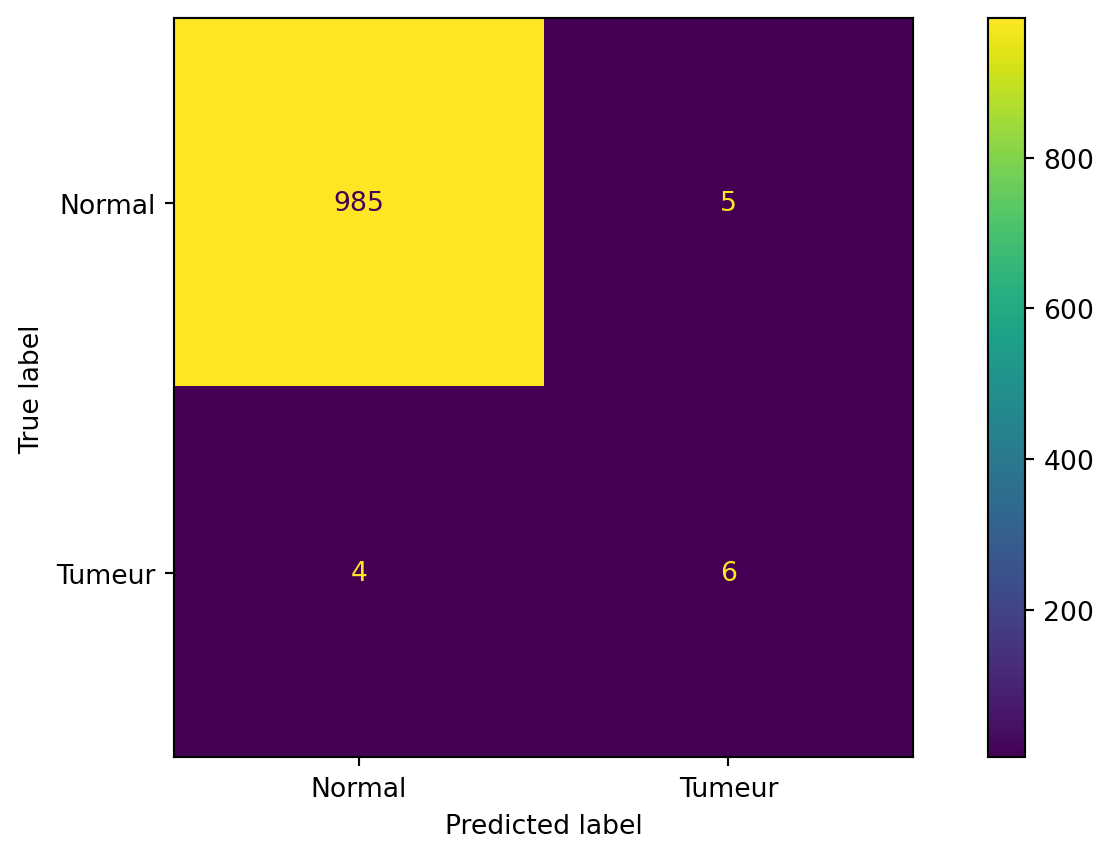
Mesures micro/macro (données médicales)
Chiffres manuscrits (réexaminés)
Chargement du jeu de données
Affichage des cinq premiers exemples

Ces images ont des dimensions de ( 28 ) pixels.
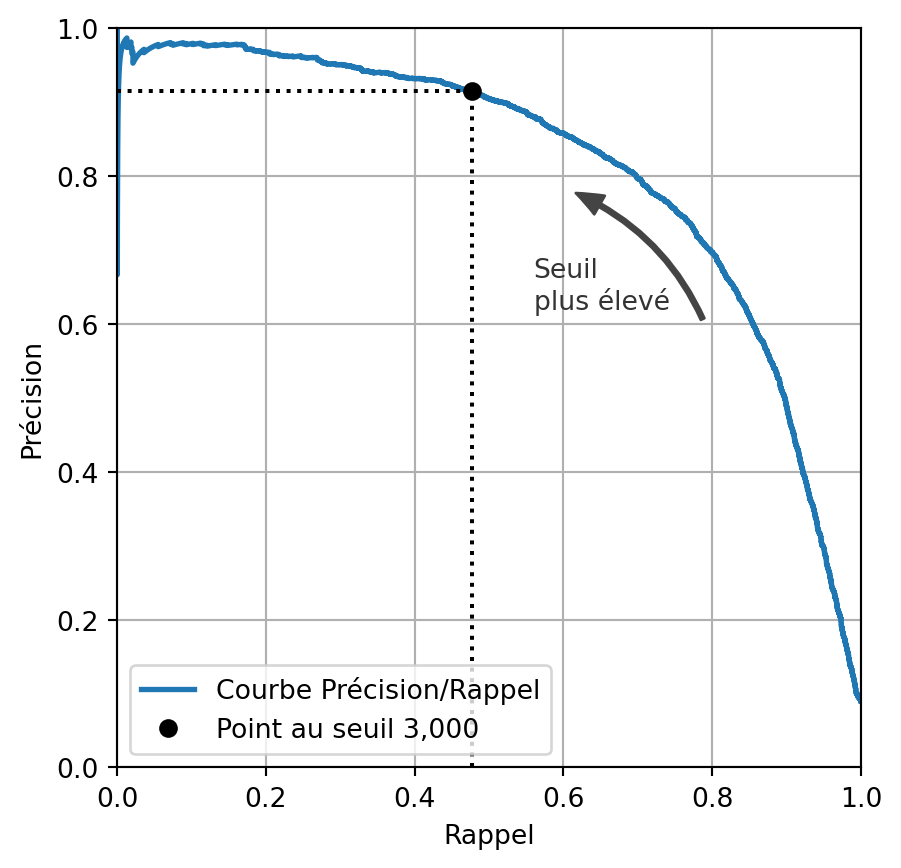
Compromis précision-rappel
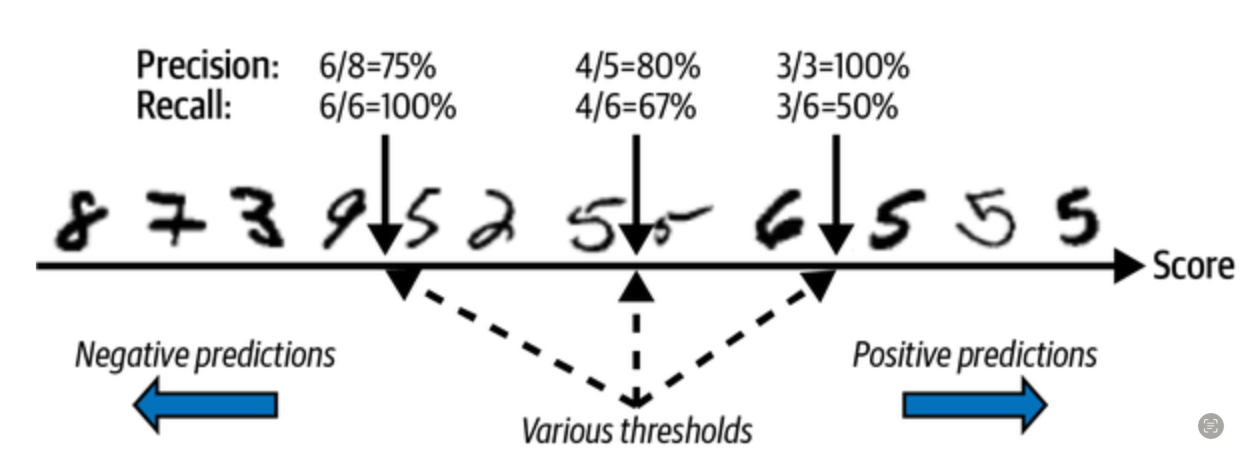
Compromis précision-rappel
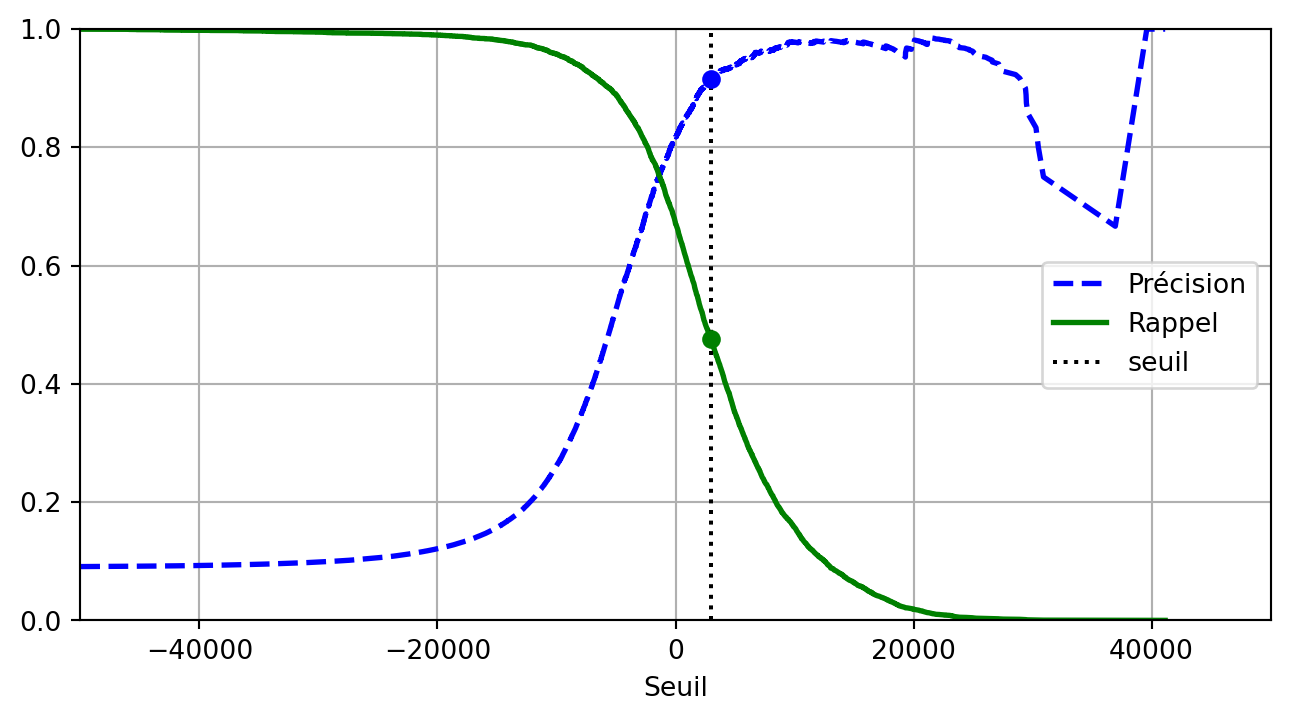
Courbe précision/rappel
Courbe ROC
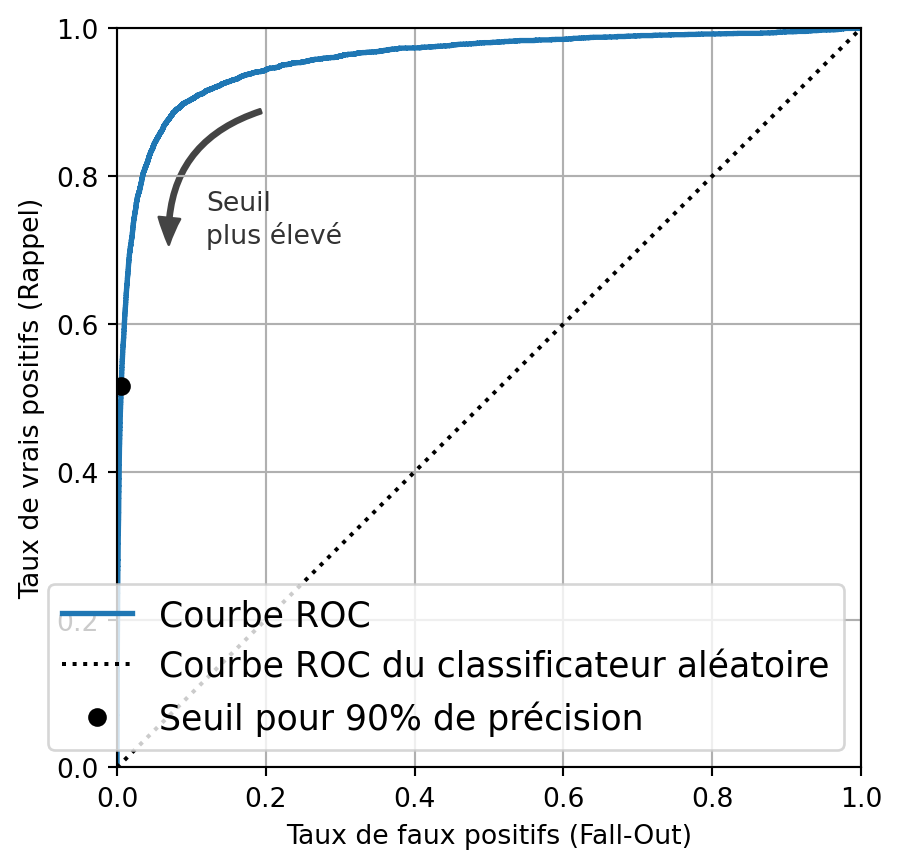
AUC/ROC

Lectures complémentaires

{kind=link}
Marcel Turcotte
École de science informatique et de génie électrique (SIGE)
Université d’Ottawa
