Entraîner un réseau de neurones artificiels (partie 1)
CSI 4106 - Automne 2024
Marcel Turcotte
Version: oct. 23, 2024 15h12
Préambule
Citation du Jour
Objectifs d’apprentissage
- Expliquer l’architecture et le fonctionnement des réseaux neuronaux à propagation directe (FNNs).
- Décrire l’algorithme de rétropropagation et son rôle dans l’apprentissage des réseaux neuronaux.
- Identifier les fonctions d’activation courantes et comprendre leur impact sur les performances du réseau.
- Comprendre le problème du gradient qui disparaît et les stratégies pour l’atténuer.
Résumé
3Blue1Brown
Résumé - DL
L’apprentissage profond (DL) est une technique d’apprentissage automatique qui peut être appliquée à l’apprentissage supervisé (y compris la régression et la classification), à l’apprentissage non supervisé et à l’apprentissage par renforcement.
Inspiré de la structure et du fonctionnement des réseaux neuronaux biologiques observés chez les animaux.
Composé de neurones interconnectés (ou unités) disposés en couches.
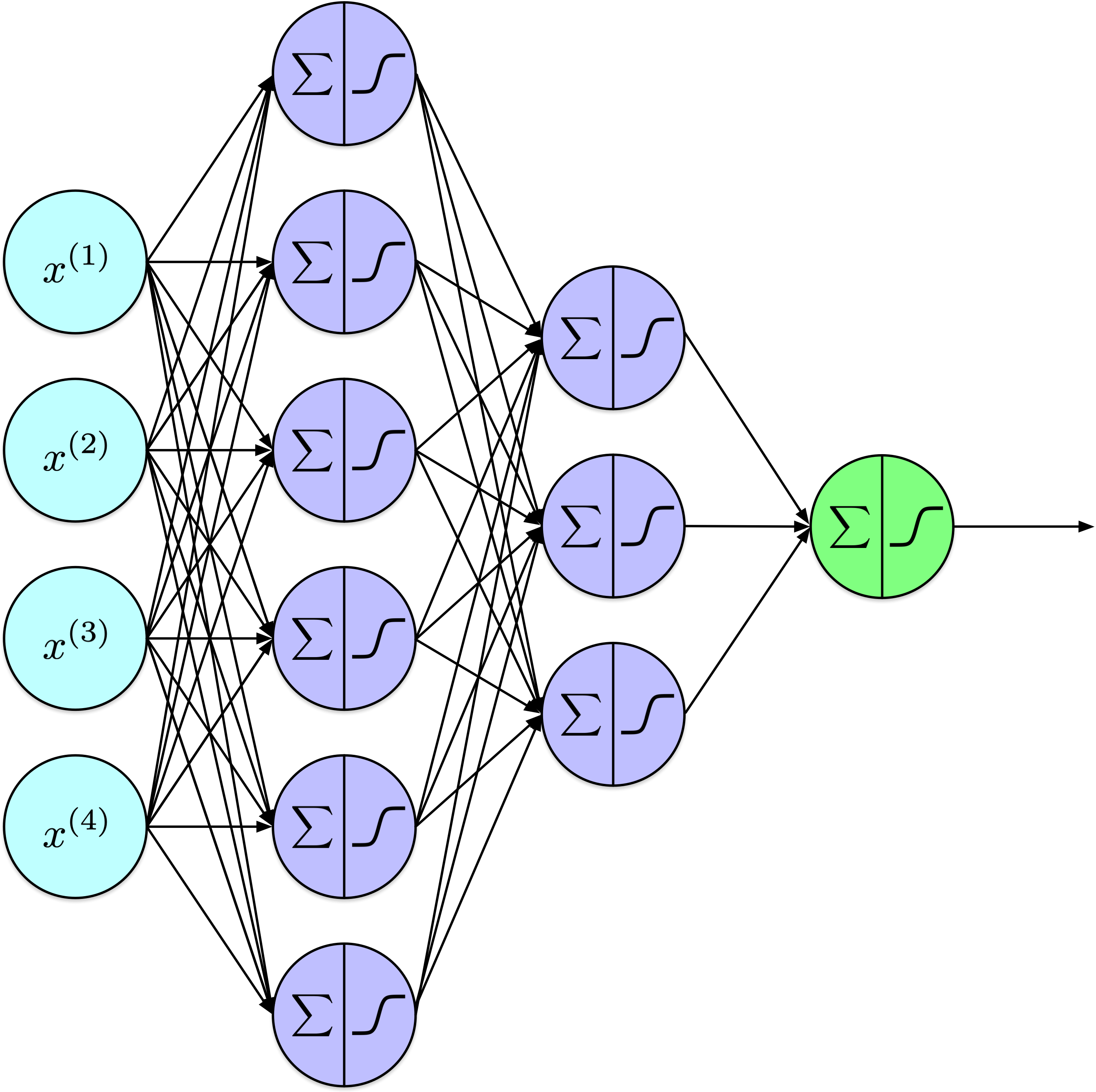
Résumé - FNN
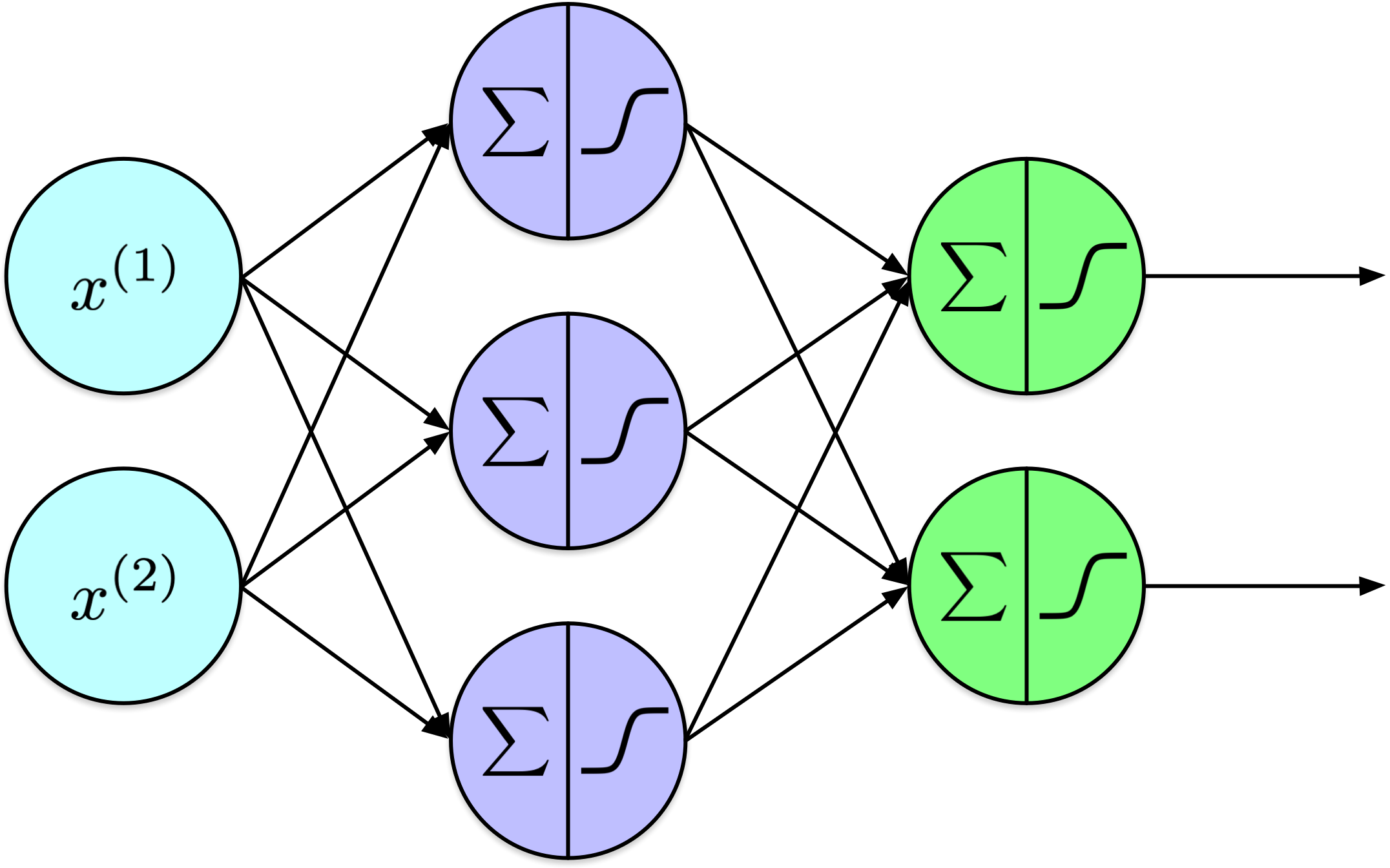
Résumé - FNN
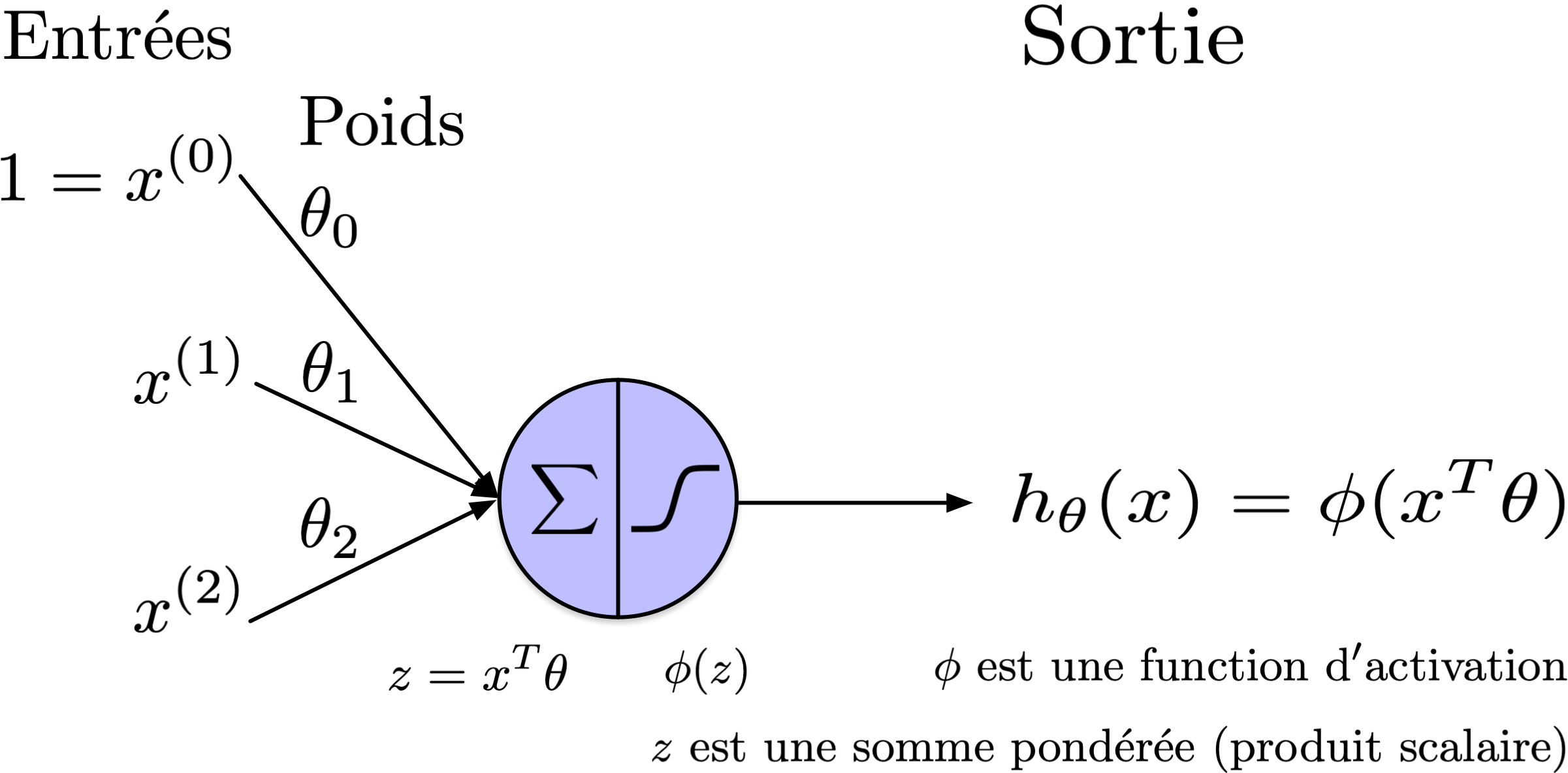
Résumé - unités
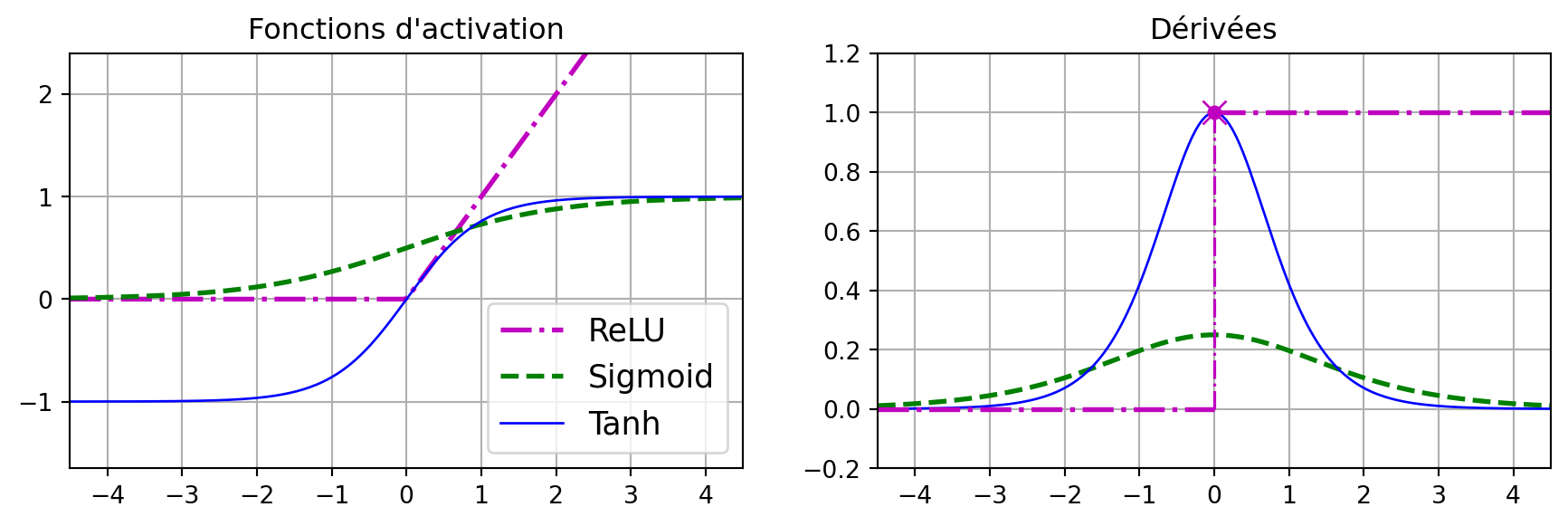
Fonctions d’activation courantes
Approximation Universelle
Le théorème de l’approximation universelle stipule qu’un réseau neuronal à propagation directe avec une seule couche cachée contenant un nombre fini de neurones peut approximer n’importe quelle fonction continue sur un sous-ensemble compact de \(\mathbb{R}^n\), à condition que les poids et les fonctions d’activation appropriés soient utilisés.
Notation
Notation
Un perceptron à deux couches calcule :
\[ y = \phi_2(\phi_1(X)) \]
où
\[ \phi_l(Z) = \phi(W_lZ_l + b_l) \]
Notation
Un perceptron à 3 couches calcule :
\[ y = \phi_3(\phi_2(\phi_1(X))) \]
où
\[ \phi_l(Z) = \phi(W_lZ_l + b_l) \]
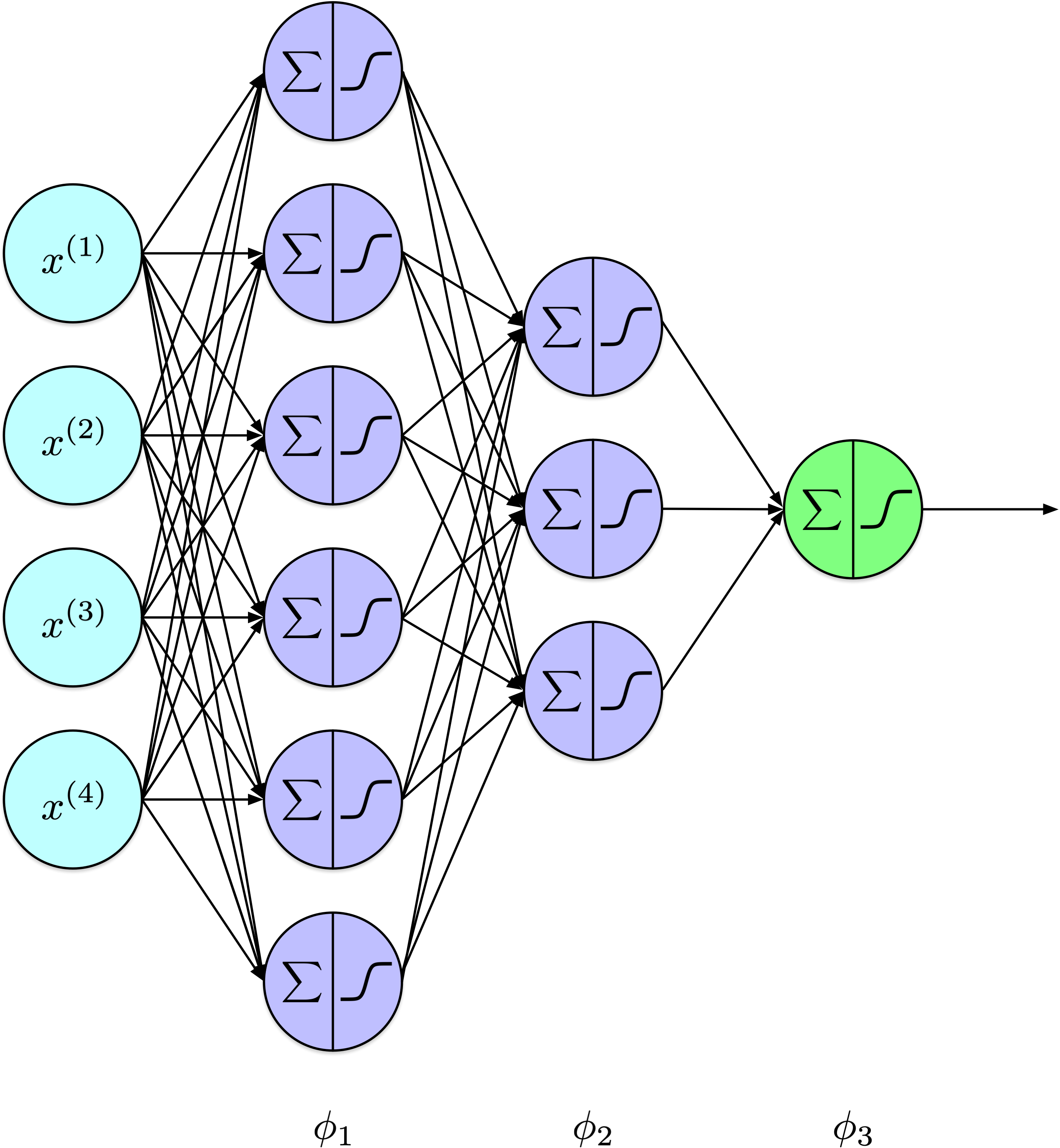
Notation
Un perceptron à \(k\) couches calcule :
\[ y = \phi_k( \ldots \phi_2(\phi_1(X)) \ldots ) \]
où
\[ \phi_l(Z) = \phi(W_lZ_l + b_l) \]
Rétropropagation
3Blue1Brown
Rétropropagation
Apprentissage de représentations par rétropropagation des erreurs
David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams
Nous décrivons une nouvelle procédure d’apprentissage, la rétropropagation, pour les réseaux de neurones simulant le comportement des neurones biologiques. La procédure ajuste à plusieurs reprises les poids des connexions dans le réseau afin de minimiser une mesure de la différence entre le vecteur de sortie réel du réseau et le vecteur de sortie désiré. À la suite de ces ajustements de poids, des unités internes ‘cachées’, qui ne font pas partie de l’entrée ou de la sortie, viennent représenter des attributs importants du domaine de la tâche, et les régularités dans la tâche sont capturées par les interactions de ces unités. La capacité à créer de nouveaux attributs utiles distingue la rétropropagation des méthodes plus anciennes et plus simples telles que la procédure de convergence du perceptron.
Avant la rétropropagation
Des limitations, comme l’incapacité à résoudre la tâche de classification XOR, ont bloqué la recherche sur les réseaux neuronaux.
Le perceptron était limité à une seule couche, et il n’existait aucune méthode connue pour entraîner un perceptron multicouche.
Les perceptrons monocouche sont limités à la résolution de tâches de classification linéairement séparables.
Rétropropagation : contributions
Le modèle utilise la moyenne des erreurs quadratiques comme fonction de perte.
La descente de gradient est utilisée pour minimiser la perte.
Une fonction d’activation sigmoid est utilisée au lieu d’une fonction de seuil, car sa dérivée fournit des informations précieuses pour la descente de gradient.
Montre comment mettre à jour les poids internes en utilisant un algorithme à deux passes composé d’une passe avant et d’une passe arrière.
Permet l’entraînement des perceptrons multicouches.
Rétropropagation : aperçu général
Initialisation
Passe avant
Calcul de la perte
Passe arrière (Rétropropagation)
Répéter les étapes 2 à 5.
Rétropropagation : 1. Initialisation
Initialiser les poids et biais du réseau neuronal.
Initialisation à zéro- Tous les poids sont initialisés à zéro.
- Problèmes de symétrie : tous les neurones produisent des sorties identiques, empêchant un apprentissage efficace.
- Initialisation aléatoire
- Les poids sont initialisés aléatoirement, souvent avec une distribution uniforme ou normale.
- Brise la symétrie entre les neurones, leur permettant d’apprendre.
- Si elle n’est pas bien ajustée, peut entraîner une convergence lente ou des gradients qui disparaissent/explosent.
Rétropropagation : 2. Passe avant
Pour chaque exemple dans l’ensemble d’entraînement (ou dans un mini-lot) :
Couche d’entrée : Passez les attributs d’entrée à la première couche.
Couches cachées : Pour chaque couche cachée, calculez les activations (sortie) en appliquant la somme pondérée des entrées plus le biais, suivie d’une fonction d’activation (par exemple, sigmoid, ReLU).
Couche de sortie : Même processus que pour les couches cachées. Les activations de la couche de sortie représentent les valeurs prédites.
Rétropropagation : 3. Calcul de la perte
Calculez la perte (erreur) à l’aide d’une fonction de perte appropriée en comparant les valeurs prédites aux valeurs cibles réelles.
Rétropropagation : 4. Passe arrière
Couche de sortie : Calculez le gradient de la perte par rapport aux poids et aux biais de la couche de sortie en utilisant la règle de chaîne du calcul.
Couches cachées : Propagez l’erreur en arrière à travers le réseau, couche par couche. Pour chaque couche, calculez le gradient de la perte par rapport aux poids et biais. Utilisez la dérivée de la fonction d’activation pour aider à calculer ces gradients.
Mettre à jour les poids et biais : Ajustez les poids et biais en utilisant les gradients calculés et un taux d’apprentissage, qui détermine la taille des ajustements.
Concepts clés
Fonctions d’activation : Des fonctions comme sigmoid, ReLU et tanh introduisent de la non-linéarité, permettant au réseau d’apprendre des modèles complexes.
Taux d’apprentissage : Un hyperparamètre qui contrôle de combien on modifie le modèle en réponse à l’erreur estimée chaque fois que les poids du modèle sont mis à jour.
Descente de gradient : Un algorithme d’optimisation utilisé pour minimiser la fonction de perte en se déplaçant itérativement vers la plus grande descente définie par le négatif du gradient.
Résumé
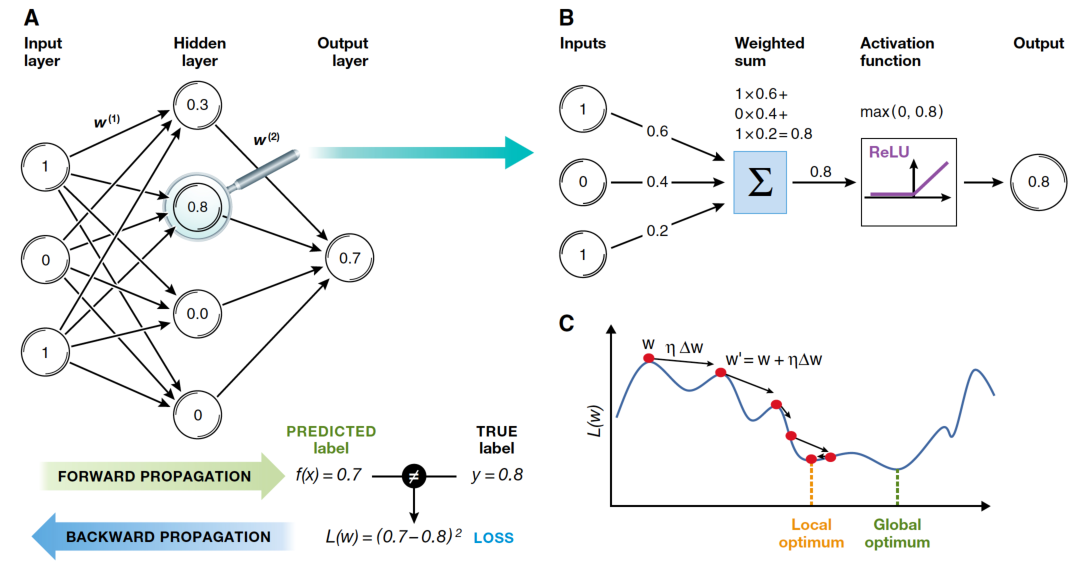
Entraînement
Gradients qui disparaissent
Problème des gradients qui disparaissent (vanishing gradients) : Les gradients deviennent trop petits, entravant la mise à jour des poids.
La recherche sur les réseaux neuronaux a de nouveau stagné au début des années 2000.
La sigmoid et sa dérivée (plage : 0 à 0,25) étaient des facteurs clés.
Initialisation courante : Les poids/biais de \(\mathcal{N}(0, 1)\) ont contribué au problème.
Glorot et Bengio
Figure 6

Figure 7
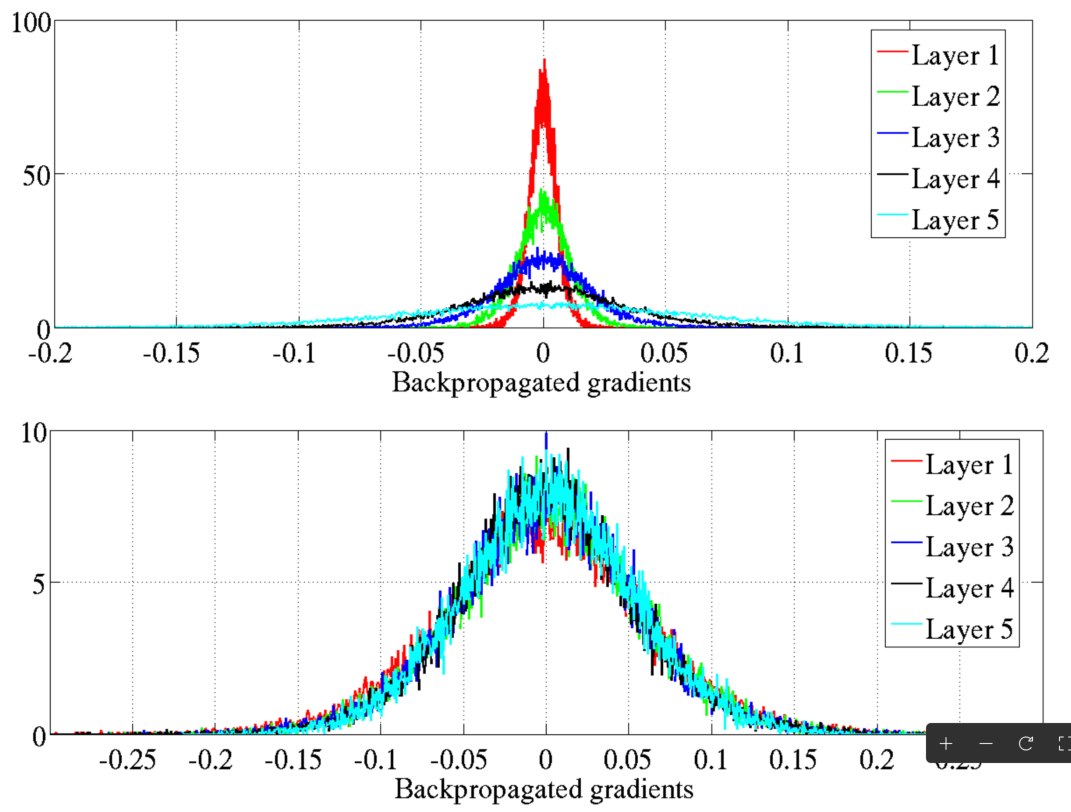
Gradients qui disparaissent : solutions
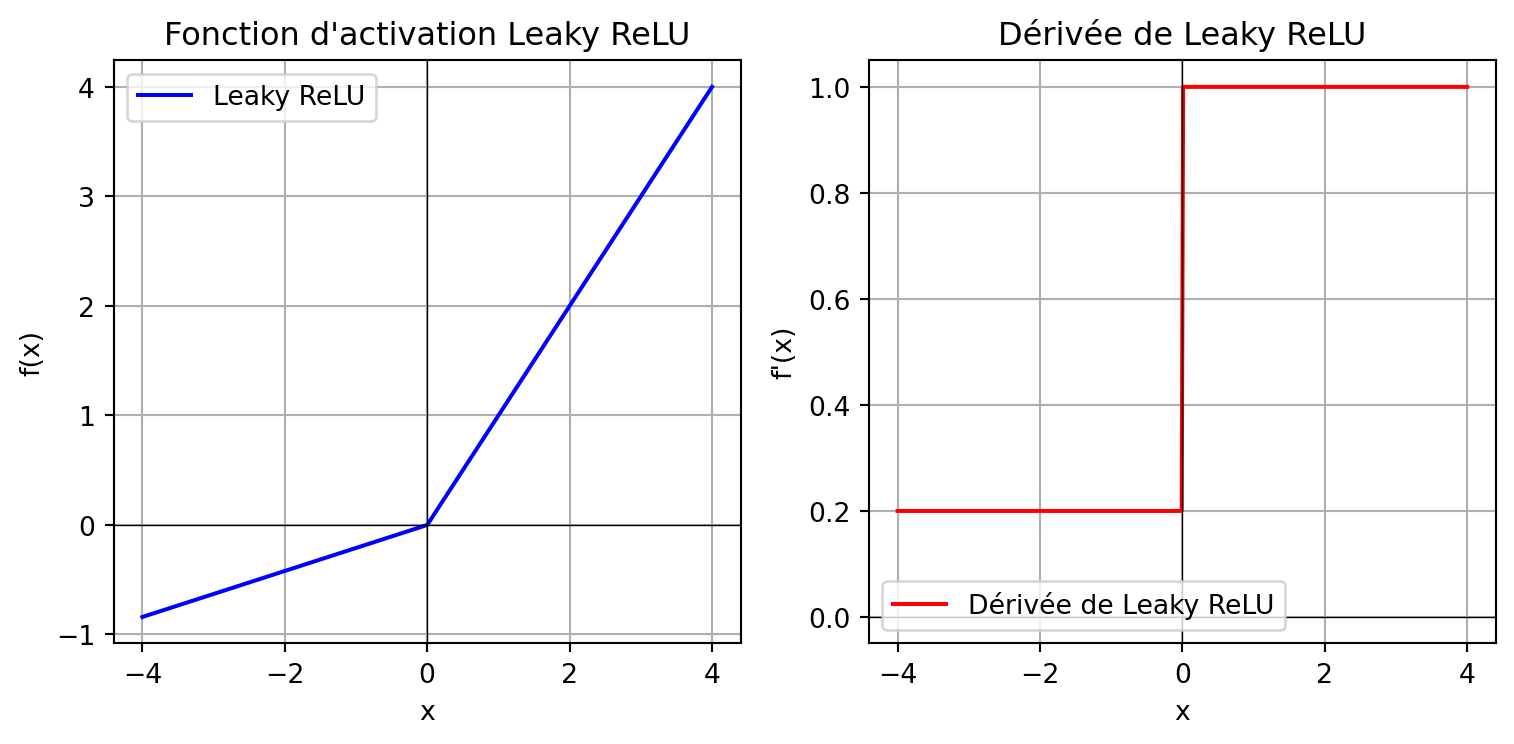
Fonctions d’activation alternatives : Unité linéaire rectifiée (ReLU) et ses variantes (par exemple, Leaky ReLU, Parametric ReLU, et Exponential Linear Unit).
Initialisation des poids : Initialisation Xavier (Glorot) ou He.
Glorot et Bengio
Objectif : Atténuer le problème des gradients instables dans les réseaux neuronaux profonds.
Flux de signal :
- Direction avant : Assurer une propagation stable du signal pour des prédictions précises.
- Direction arrière : Maintenir un flux de gradient cohérent pendant la rétropropagation.
Glorot et Bengio
Ajustement de la variance :
Passe avant : Assurez-vous que la variance de sortie de chaque couche correspond à la variance d’entrée.
Passe arrière : Maintenez une variance de gradient égale avant et après le passage dans chaque couche.
Initialisation He
Une méthode d’initialisation similaire mais légèrement différente, conçue pour fonctionner avec ReLU, ainsi que Leaky ReLU, ELU, GELU, Swish, et Mish.
Note
L’initialisation aléatoire des poids1 suffit à briser la symétrie dans un réseau neuronal, permettant ainsi de fixer les termes de biais à zéro sans nuire à la capacité d’apprentissage du réseau.
Fonction d’activation : Leaky ReLU
Prologue
Résumé
- Réseaux neuronaux artificiels (ANNs) :
- Inspirés des réseaux neuronaux biologiques.
- Composés de neurones interconnectés organisés en couches.
- Applicables à l’apprentissage supervisé, non supervisé, et par renforcement.
- Réseaux neuronaux à propagation directe (FNNs) :
- L’information circule unidirectionnellement de l’entrée à la sortie.
- Composés de couches d’entrée, cachées et de sortie.
- Le nombre de couches et de neurones par couche peut varier.
- Fonctions d’activation :
- Introduisent de la non-linéarité pour permettre l’apprentissage de modèles complexes.
- Fonctions courantes : Sigmoid, Tanh, ReLU, Leaky ReLU.
- Le choix de la fonction d’activation affecte le flux de gradient et les performances du réseau.
- Algorithme de rétropropagation :
- L’entraînement implique une passe avant, un calcul de perte, une passe arrière et une mise à jour des poids.
- Utilise la descente de gradient pour minimiser la fonction de perte.
- Permet l’entraînement des perceptrons multicouches en ajustant les poids internes.
- Problème du gradient qui disparaît :
- Les gradients deviennent trop petits lors de la rétropropagation, ce qui freine l’entraînement.
- Stratégies de mitigation : utilisation de fonctions d’activation ReLU et d’une initialisation correcte des poids (Glorot ou He).
- Initialisation des poids :
- L’initialisation aléatoire brise la symétrie et permet un apprentissage efficace.
- L’initialisation Glorot convient aux activations sigmoid et tanh.
- L’initialisation He est optimale pour ReLU et ses variantes.
- Concepts clés :
- Le taux d’apprentissage détermine la taille des pas pendant l’optimisation.
- La descente de gradient est utilisée pour mettre à jour les poids en minimisant la perte.
- Le choix des fonctions d’activation et des méthodes d’initialisation est crucial pour un entraînement efficace.
3Blue1Brown
Une série de vidéos, avec des animations, offrant l’intuition derrière l’algorithme de rétropropagation.
Neural networks (playlist)
- What is backpropagation really doing? (12m 47s)
- Backpropagation calculus (10m 18s)
StatQuest
Herman Kamper
Une des séries de vidéos les plus complètes sur l’algorithme de rétropropagation.
Introduction to neural networks (playlist)
- Backpropagation (without forks) (31m 1s)
- Backprop for a multilayer feedforward neural network (4m 2s)
- Computational graphs and automatic differentiation for neural networks (6m 56s)
- Common derivatives for neural networks (7m 18s)
- A general notation for derivatives (in neural networks) (7m 56s)
- Forks in neural networks (13m 46s)
- Backpropagation in general (now with forks) (3m 42s)
Prochaine leçon
- Nous discutons de concepts tels que softmax et entropie croisée, ainsi que des approches pour la régularisation.
Références
Angermueller, Christof, Tanel Pärnamaa, Leopold Parts, et Oliver Stegle. 2016. « Deep learning for computational biology ». Mol Syst Biol 12 (7): 878. https://doi.org/10.15252/msb.20156651.
Cybenko, George V. 1989. « Approximation by superpositions of a sigmoidal function ». Mathematics of Control, Signals and Systems 2: 303‑14. https://api.semanticscholar.org/CorpusID:3958369.
Géron, Aurélien. 2022. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 3ᵉ éd. O’Reilly Media, Inc.
Glorot, Xavier, et Yoshua Bengio. 2010. « Understanding the difficulty of training deep feedforward neural networks ». In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, édité par Yee Whye Teh et Mike Titterington, 9:249‑56. Proceedings of Machine Learning Research. Chia Laguna Resort, Sardinia, Italy: PMLR. https://proceedings.mlr.press/v9/glorot10a.html.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, et Jian Sun. 2016. « Deep Residual Learning for Image Recognition ». In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770‑78. https://doi.org/10.1109/CVPR.2016.90.
Hornik, Kurt, Maxwell Stinchcombe, et Halbert White. 1989. « Multilayer feedforward networks are universal approximators ». Neural Networks 2 (5): 359‑66. https://doi.org/https://doi.org/10.1016/0893-6080(89)90020-8.
Rumelhart, David E., Geoffrey E. Hinton, et Ronald J. Williams. 1986. « Learning representations by back-propagating errors ». Nature 323 (6088): 533‑36. https://doi.org/10.1038/323533a0.
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.
Marcel Turcotte
École de science informatique et de génie électrique (SIGE)
Université d’Ottawa
