
Architectures de réseaux neuronaux
CSI 4506 - Automne 2024
Marcel Turcotte
Version: nov. 7, 2024 17h55
Préambule
Citation du jour
;document.getElementById("tweet-29860").innerHTML = tweet["html"];Objectifs d’apprentissage
- Expliquer la hiérarchie des concepts dans l’apprentissage profond
- Comparer les réseaux neuronaux profonds et peu profonds
- Décrire la structure et la fonction des réseaux neuronaux convolutifs (CNNs)
- Comprendre les opérations de convolution utilisant des noyaux
- Expliquer les champs récepteurs, le padding et le stride dans les CNNs
- Discuter du rôle et des avantages de la couche de pooling
Introduction
Hiérarchie des concepts
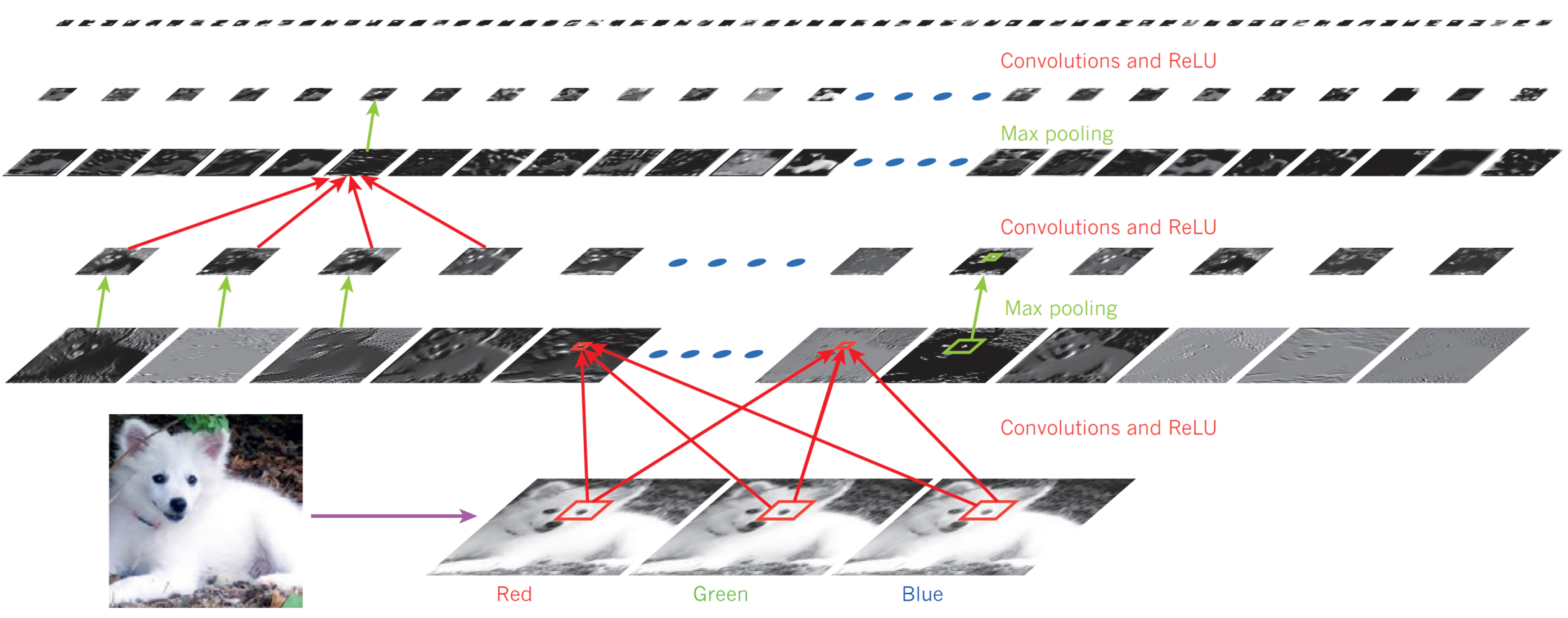
Hiérarchie des concepts
- Chaque couche détecte des motifs à partir de la sortie de la couche précédente.
- En d’autres termes, en progressant de l’entrée à la sortie du réseau, le réseau découvre des “motifs de motifs”.
- En analysant une image, les réseaux détectent d’abord des motifs simples, tels que des lignes verticales, horizontales, diagonales, des arcs, etc.
- Ceux-ci sont ensuite combinés pour former des coins, des croix, etc.
- En d’autres termes, en progressant de l’entrée à la sortie du réseau, le réseau découvre des “motifs de motifs”.
- (Cela explique comment fonctionne l’apprentissage par transfert et pourquoi il est pertinent de ne sélectionner que les couches inférieures.)
Mais aussi…
“Un MLP avec une seule couche cachée peut théoriquement modéliser même les fonctions les plus complexes, à condition qu’il dispose d’assez de neurones. Mais pour des problèmes complexes, les réseaux profonds ont une efficacité paramétrique bien plus élevée que les réseaux peu profonds : ils peuvent modéliser des fonctions complexes en utilisant exponentiellement moins de neurones que les réseaux peu profonds, leur permettant d’atteindre de bien meilleures performances avec la même quantité de données d’entraînement.”
Combien de couches ?
- Commencez avec une seule couche, puis augmentez le nombre de couches jusqu’à ce que le modèle commence à sur-apprendre les données d’entraînement.
- Ajustez finement le modèle en ajoutant des techniques de régularisation (couches de dropout, termes de régularisation, etc.).
Observation
Prenons un réseau de neurones feed-forward (FFN) et son modèle :
\[ h_{W,b}(X) = \phi_k(\ldots \phi_2(\phi_1(X)) \ldots) \]
où
\[ \phi_l(Z) = \sigma(W_l Z + b_l) \]
pour \(l=1 \ldots k\). - Le nombre de paramètres augmente rapidement :
\[ (\text{taille de la couche}_{l-1} + 1) \times \text{taille de la couche}_{l} \]
Deux couches de 1 000 unités impliquent 1 000 000 paramètres !
Réseau neuronal convolutif
Réseau neuronal convolutif (CNN)
Réseau neuronal convolutif (CNN)
Les informations cruciales sur les motifs sont souvent locales.
- Par exemple, les arêtes, coins, croix.
Les couches convolutionnelles réduisent significativement les paramètres.
Contrairement aux couches denses, les neurones dans une couche convolutionnelle ne sont pas complètement connectés à la couche précédente.
Les neurones ne se connectent qu’à leurs champs récepteurs (zones rectangulaires).
Noyau
Noyau
Noyau
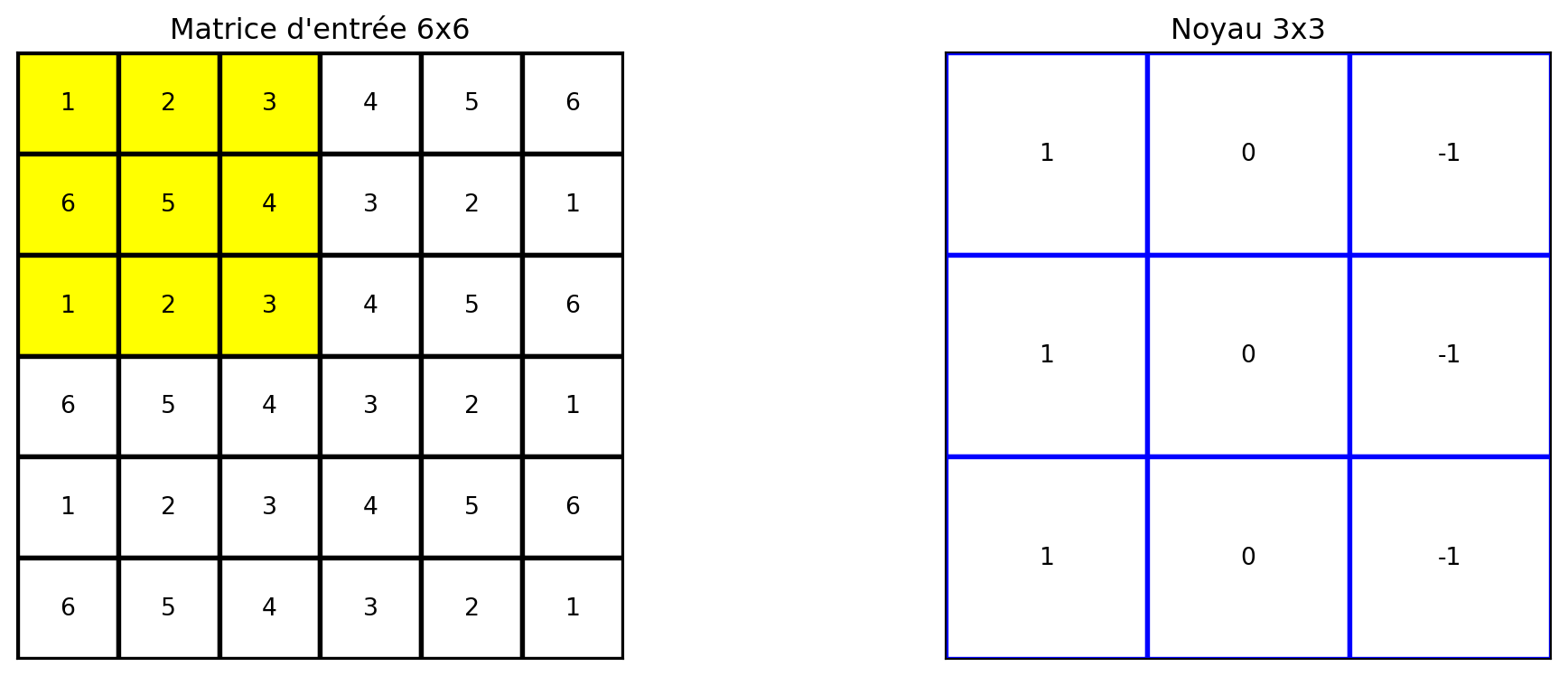
Noyau

Noyau

Noyau

Noyau

Déplacer le noyau

Noyau

Noyau

Noyau

Floutage

Détection des bords verticaux

Détection des bords horizontaux

Traitement d’images
Mais qu’est-ce qu’une convolution ?
Noyaux
Contrairement au traitement d’images, où les noyaux sont définis manuellement par l’utilisateur, dans le cas des réseaux convolutifs, les noyaux sont automatiquement appris par le réseau.
Champ récepteur
Champ récepteur

Champ récepteur
- Chaque unité est connectée aux neurones de ses champs récepteurs.
- L’unité \(i,j\) dans la couche \(l\) est connectée aux unités de \(i\) à \(i+f_h-1\), \(j\) à \(j+f_w-1\) de la couche \(l-1\), où \(f_h\) et \(f_w\) sont respectivement la hauteur et la largeur du champ récepteur.
Padding
Zero padding. Pour conserver des couches de même taille, la grille peut être remplie de zéros.
Padding
Pas de padding

Padding moitié

Padding complet

Stride
Stride. Il est possible de connecter une couche \((l-1)\) plus grande à une couche \((l)\) plus petite en sautant des unités. Le nombre d’unités sautées est appelé stride, \(s_h\) et \(s_w\).
- L’unité \(i,j\) dans la couche \(l\) est connectée aux unités de \(i \times s_h\) à \(i \times s_h + f_h - 1\), \(j \times s_w\) à \(j \times s_w + f_w - 1\) de la couche \(l-1\), où \(f_h\) et \(f_w\) sont respectivement la hauteur et la largeur du champ récepteur, \(s_h\) et \(s_w\) sont respectivement la hauteur et la largeur du stride.
Stride
Pas de padding, stride

Padding, stride

Filtres
Filtres
Une fenêtre de taille \(f_h \times f_w\) est déplacée sur la sortie des couches \(l-1\), appelée carte de attributs d’entrée, position par position.
Pour chaque emplacement, le produit est calculé entre la partie extraite et une matrice de la même taille, appelée noyau convolutionnel ou filtre. La somme des valeurs dans la matrice résultante constitue la sortie pour cet emplacement.
Modèle
Modèle

\[ z_{i,j,k} = b_k + \sum_{u=0}^{f_h-1} \sum_{v=0}^{f_w-1} \sum_{k'=0}^{f_{n'}-1} x_{i',j',k'} \cdot w_{u,v,k',k} \]
où \(i' = i \times s_h + u\) et \(j' = j \times s_w + v\).
Couche convolutionnelle
“Ainsi, une couche remplie de neurones utilisant le même filtre produit une carte de d’attributs.”
“Bien sûr, il n’est pas nécessaire de définir les filtres manuellement : au lieu de cela, pendant l’entraînement, la couche convolutionnelle apprendra automatiquement les filtres les plus utiles pour sa tâche.”
Couche convolutionnelle
“(…) et les couches supérieures apprendront à les combiner en des motifs plus complexes.”
“Le fait que tous les neurones d’une carte d’attributs partagent les mêmes paramètres réduit considérablement le nombre de paramètres du modèle.”
Résumé
- Carte d’attributs (feature map) : Dans les réseaux neuronaux convolutifs (CNNs), la sortie d’une opération de convolution est appelée une carte d’attributs. Elle capture les attributs de l’entrée sous une forme simplifiée et localisée par rapport au filtre appliqué.
Résumé
- Paramètres du noyau : Les paramètres du noyau sont appris via le processus de rétropropagation, permettant au réseau d’optimiser ses capacités d’extraction d’attributs en fonction des données d’entraînement.
Résumé
- Terme de biais : Un seul terme de biais est ajouté uniformément à toutes les entrées de la carte d’attributs. Ce biais aide à ajuster le niveau d’activation, offrant une flexibilité supplémentaire au réseau pour mieux ajuster les données.
Résumé
- Fonction d’activation : Après l’ajout du biais, les valeurs de la carte d’attributs passent généralement par une fonction d’activation, telle que ReLU (Rectified Linear Unit). La fonction ReLU introduit une non-linéarité en mettant à zéro les valeurs négatives tout en conservant les valeurs positives, permettant ainsi au réseau d’apprendre des motifs plus complexes.
Pooling
Pooling
Une couche de pooling présente des similitudes avec une couche convolutionnelle.
- Chaque neurone dans une couche de pooling est connecté à un ensemble de neurones au sein d’un champ récepteur.
Cependant, contrairement aux couches convolutionnelles, les couches de pooling ne possèdent pas de poids.
- Elles produisent plutôt une sortie en appliquant une fonction d’agrégation, généralement maximale ou moyenne.
Pooling
Ce processus de sous-échantillonnage conduit à une réduction de la taille du réseau ; chaque fenêtre de dimensions \(f_h \times f_w\) est condensée en une seule valeur, généralement le maximum ou la moyenne de cette fenêtre.
Selon Géron (2019), une couche de pooling max offre un certain degré d’invariance aux petites translations (§ 14).
Pooling
- Réduction dimensionnelle : Les couches de pooling réduisent les dimensions spatiales (largeur et hauteur) des cartes d’attributs d’entrée. Cette réduction diminue le nombre de paramètres et la charge computationnelle dans le réseau, ce qui peut aider à prévenir le sur-apprentissage.
Pooling
- Extraction des attratributs : En résumant la présence d’attributs dans une région, les couches de pooling permettent de conserver les informations les plus critiques tout en éliminant les détails moins importants. Ce processus permet au réseau de se concentrer sur les attributs les plus saillantes.
Pooling
- Invariance à la translation : Le pooling introduit un degré d’invariance aux translations et distorsions dans l’entrée. Par exemple, le max pooling capture la caractéristique la plus marquante dans une région locale, rendant le réseau moins sensible aux petits décalages ou variations dans l’entrée.
Pooling
- Réduction du bruit : Le pooling peut aider à lisser le bruit dans l’entrée en agrégeant l’information sur une région, mettant ainsi en évidence les attributs cohérents par rapport aux variations aléatoires.
Pooling
- Apprentissage hiérarchique des attributs : En réduisant progressivement les dimensions spatiales à travers les couches, les couches de pooling permettent au réseau de construire une représentation hiérarchique des données d’entrée, capturant des attributs de plus en plus abstraites et complexes à des couches plus profondes.
Keras
import tensorflow as tf
from functools import partial
DefaultConv2D = partial(tf.keras.layers.Conv2D, kernel_size=3, padding="same", activation="relu", kernel_initializer="he_normal")
model = tf.keras.Sequential([
DefaultConv2D(filters=64, kernel_size=7, input_shape=[28, 28, 1]),
tf.keras.layers.MaxPool2D(),
DefaultConv2D(filters=128),
DefaultConv2D(filters=128),
tf.keras.layers.MaxPool2D(),
DefaultConv2D(filters=256),
DefaultConv2D(filters=256),
tf.keras.layers.MaxPool2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=128, activation="relu", kernel_initializer="he_normal"),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=64, activation="relu", kernel_initializer="he_normal"),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=10, activation="softmax") ])
model.summary()Keras
Model: "sequential_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ conv2d_5 (Conv2D) │ (None, 28, 28, 64) │ 3,200 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_3 (MaxPooling2D) │ (None, 14, 14, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_6 (Conv2D) │ (None, 14, 14, 128) │ 73,856 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_7 (Conv2D) │ (None, 14, 14, 128) │ 147,584 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_4 (MaxPooling2D) │ (None, 7, 7, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_8 (Conv2D) │ (None, 7, 7, 256) │ 295,168 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_9 (Conv2D) │ (None, 7, 7, 256) │ 590,080 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_5 (MaxPooling2D) │ (None, 3, 3, 256) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ flatten_1 (Flatten) │ (None, 2304) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_3 (Dense) │ (None, 128) │ 295,040 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_2 (Dropout) │ (None, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_4 (Dense) │ (None, 64) │ 8,256 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_3 (Dropout) │ (None, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_5 (Dense) │ (None, 10) │ 650 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 1,413,834 (5.39 MB)
Trainable params: 1,413,834 (5.39 MB)
Non-trainable params: 0 (0.00 B)
Réseaux neuronaux convolutifs

AlexNet

Krizhevsky, Sutskever, et Hinton (2012)
VGG

Simonyan et Zisserman (2015)
Performance des ConvNets

StatQuest
Dernier mot
Comme vous pouvez l’imaginer, le nombre de couches et de filtres sont des hyperparamètres qui sont optimisés par le biais de l’ajustement des hyperparamètres.

Prologue
Résumé
- Hiérarchie des concepts en apprentissage profond
- Noyaux et opérations de convolution
- Champ récepteur, remplissage (padding) et pas (stride)
- Filtres et cartes des attributs
- Couches convolutionnelles
- Couches de pooling
Directions futures
Lors de l’intégration des CNN dans vos projets, envisagez d’explorer les sujets suivants :
Attribution de attributs : Diverses techniques sont disponibles pour visualiser ce que le réseau a appris. Par exemple, dans le contexte des voitures autonomes, il est crucial de s’assurer que le réseau se concentre sur des attributs pertinentes, évitant les distractions.
Apprentissage par transfert : Cette approche permet la réutilisation des poids de réseaux pré-entraînés, ce qui accélère le processus d’apprentissage, réduit les besoins en calcul et facilite l’entraînement du réseau même avec un nombre limité d’exemples.
Lectures Complémentaires

Understanding Deep Learning (Prince 2023) est un manuel récemment publié qui se concentre sur les concepts fondamentaux de l’apprentissage profond.
Il commence par les principes de base et s’étend à des sujets contemporains tels que les transformateurs, les modèles de diffusion, les réseaux de neurones graphiques, les autoencodeurs, les réseaux adversariaux et l’apprentissage par renforcement.
Le manuel vise à aider les lecteurs à comprendre ces concepts sans entrer excessivement dans les détails théoriques.
Il comprend soixante-huit exercices sous forme de cahiers Python.
Le livre suit un modèle “lire d’abord, payer plus tard”.
Ressources
- Un guide de l’arithmétique de convolution pour l’apprentissage profond
- Auteurs : Vincent Dumoulin et Francesco Visin
- Dernière révision : 11 janvier 2018
Prochain cours
- Nous introduirons les espaces de solutions.
Références
Géron, Aurélien. 2019. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 2nd éd. O’Reilly Media.
———. 2022. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 3ᵉ éd. O’Reilly Media, Inc.
Goodfellow, Ian, Yoshua Bengio, et Aaron Courville. 2016. Deep Learning. Adaptive computation et machine learning. MIT Press. https://dblp.org/rec/books/daglib/0040158.
Krizhevsky, Alex, Ilya Sutskever, et Geoffrey E Hinton. 2012. « ImageNet Classification with Deep Convolutional Neural Networks ». In Advances in Neural Information Processing Systems, édité par F. Pereira, C. J. Burges, L. Bottou, et K. Q. Weinberger. Vol. 25. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf.
LeCun, Yann, Yoshua Bengio, et Geoffrey Hinton. 2015. « Deep learning ». Nature 521 (7553): 436‑44. https://doi.org/10.1038/nature14539.
Lecun, Y., L. Bottou, Y. Bengio, et P. Haffner. 1998. « Gradient-based learning applied to document recognition ». Proceedings of the IEEE 86 (11): 2278‑2324. https://doi.org/10.1109/5.726791.
Prince, Simon J. D. 2023. Understanding Deep Learning. The MIT Press. http://udlbook.com.
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.
Simonyan, Karen, et Andrew Zisserman. 2015. « Very Deep Convolutional Networks for Large-Scale Image Recognition ». In International Conference on Learning Representations.
Marcel Turcotte
École de science informatique et de génie électrique (SIGE)
Université d’Ottawa
