Recherche informée
CSI 4106 - Automne 2024
Marcel Turcotte
Version: nov. 22, 2024 09h02
Préambule
Citation du jour
Objectifs d’apprentissage
Comprendre les stratégies de recherche informée et le rôle des fonctions heuristiques dans l’efficacité de la recherche.
Implémenter et comparer BFS, DFS, et la recherche par meilleur choix (Best-First Search) en utilisant le problème du puzzle à 8 cases.
Analyser la performance et l’optimalité de divers algorithmes de recherche.
Résumé
Problème de recherche
Un ensemble d’états, appelé espace d’états.
Un état initial où l’agent commence.
Un ou plusieurs états objectifs qui définissent des résultats réussis.
Un ensemble d’actions disponibles dans un état donné \(s\).
Un modèle de transition qui détermine l’état suivant en fonction de l’état actuel et de l’action sélectionnée.
Une fonction de coût d’action qui spécifie le coût de l’exécution de l’action \(a\) dans l’état \(s\) pour atteindre l’état \(s'\).
Définitions
Un chemin est défini comme une séquence d’actions.
Une solution est un chemin qui relie l’état initial à l’état objectif.
Une solution optimale est le chemin avec le coût le plus bas parmi toutes les solutions possibles.
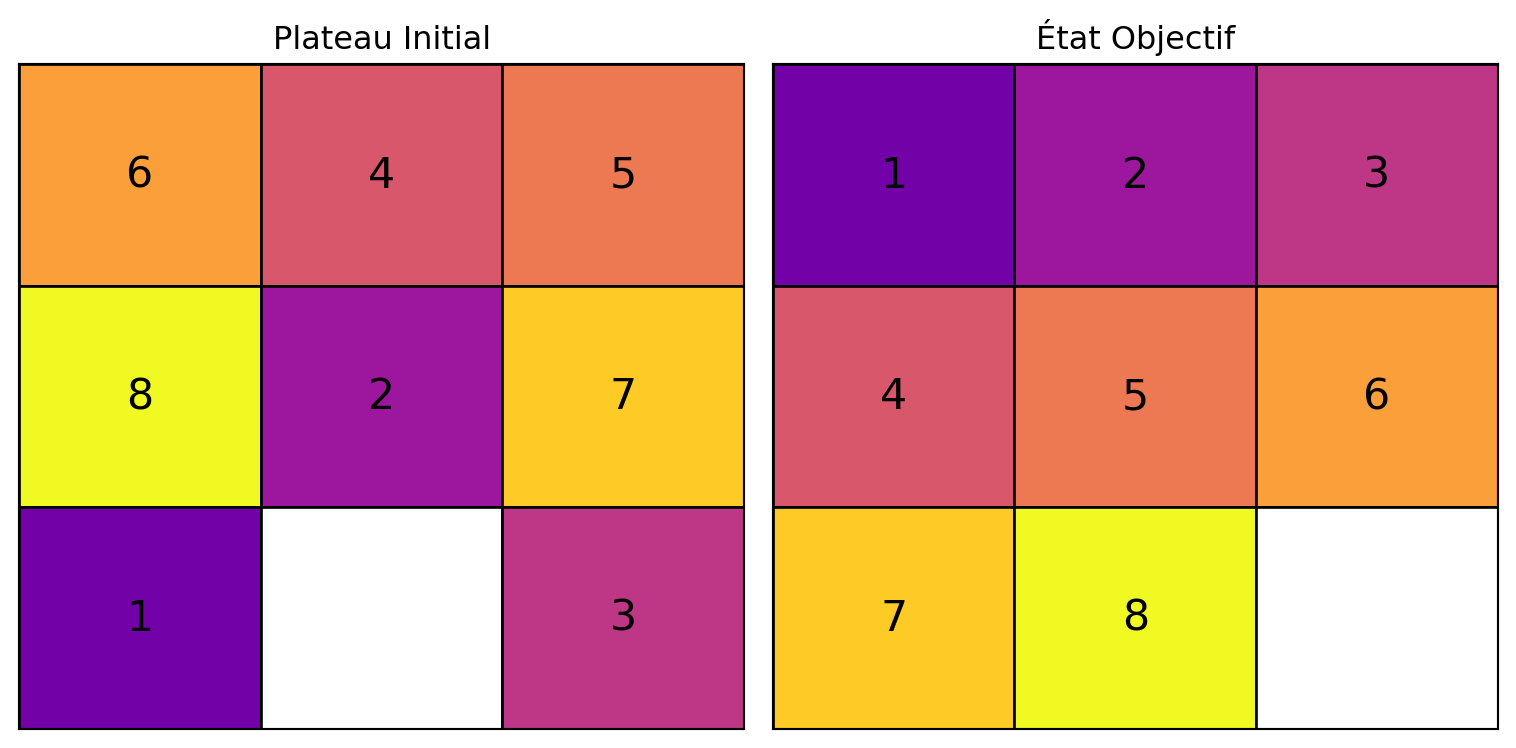
Exemple : 8-Puzzle
Arbre de recherche
Arbre de recherche
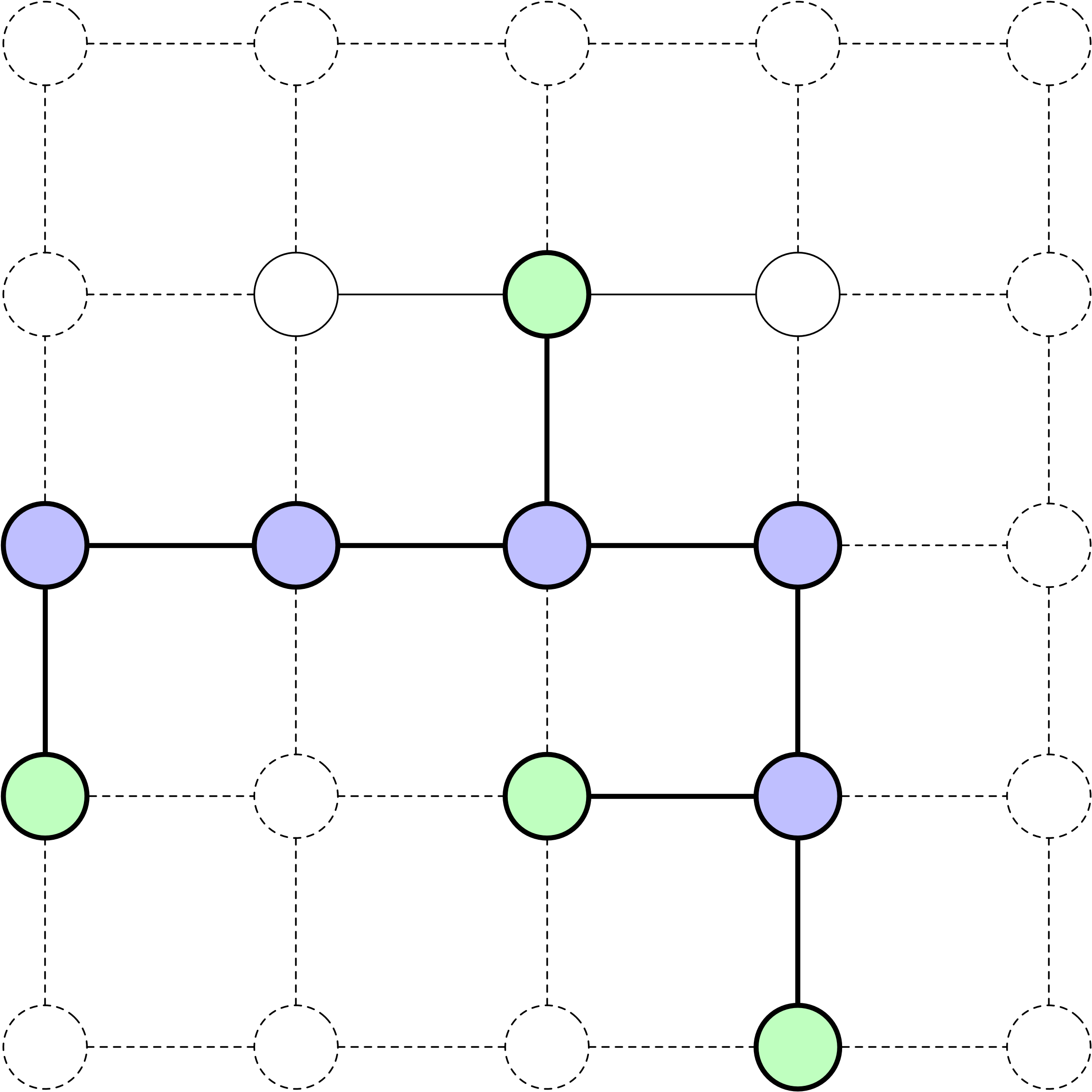
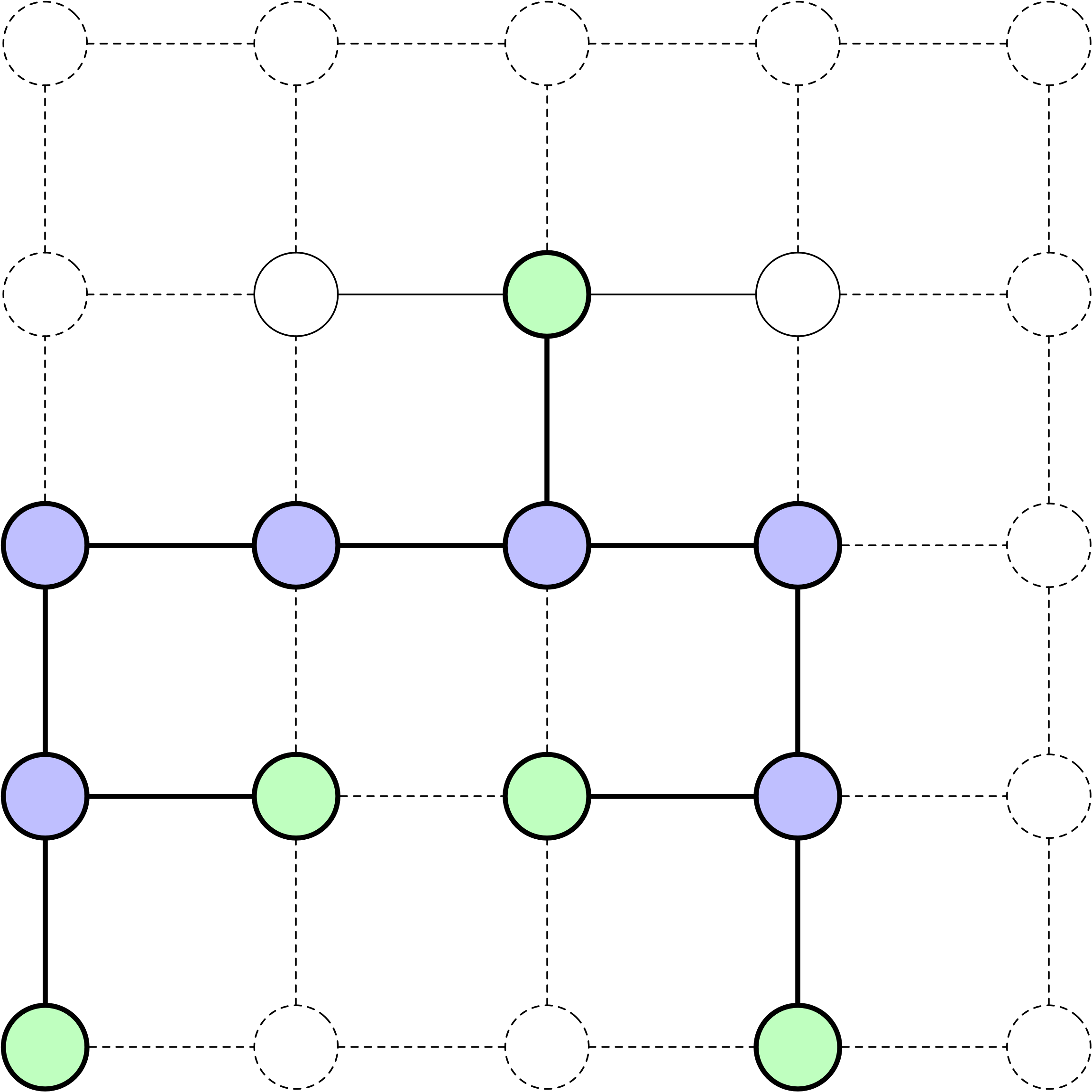
Frontière
Frontière
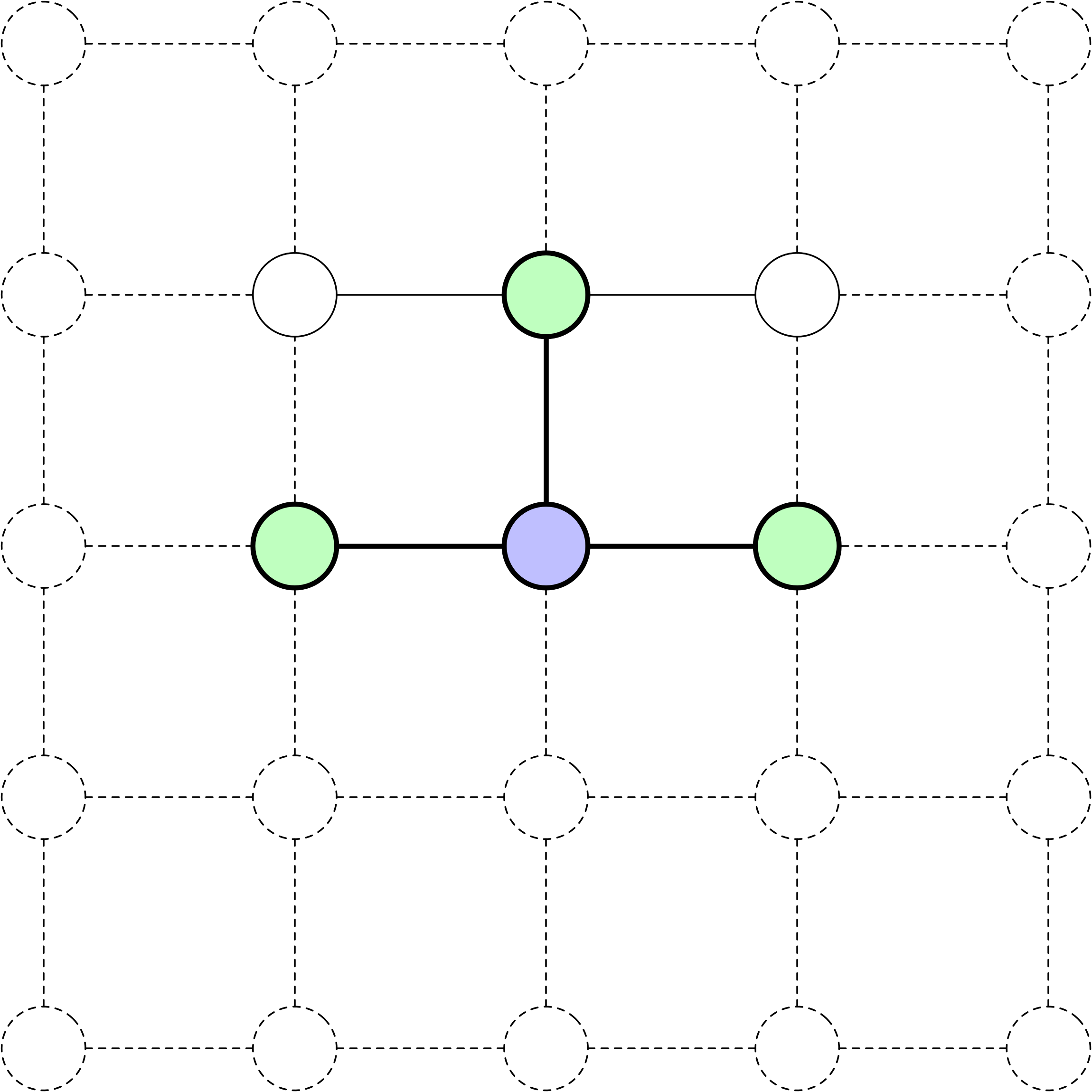
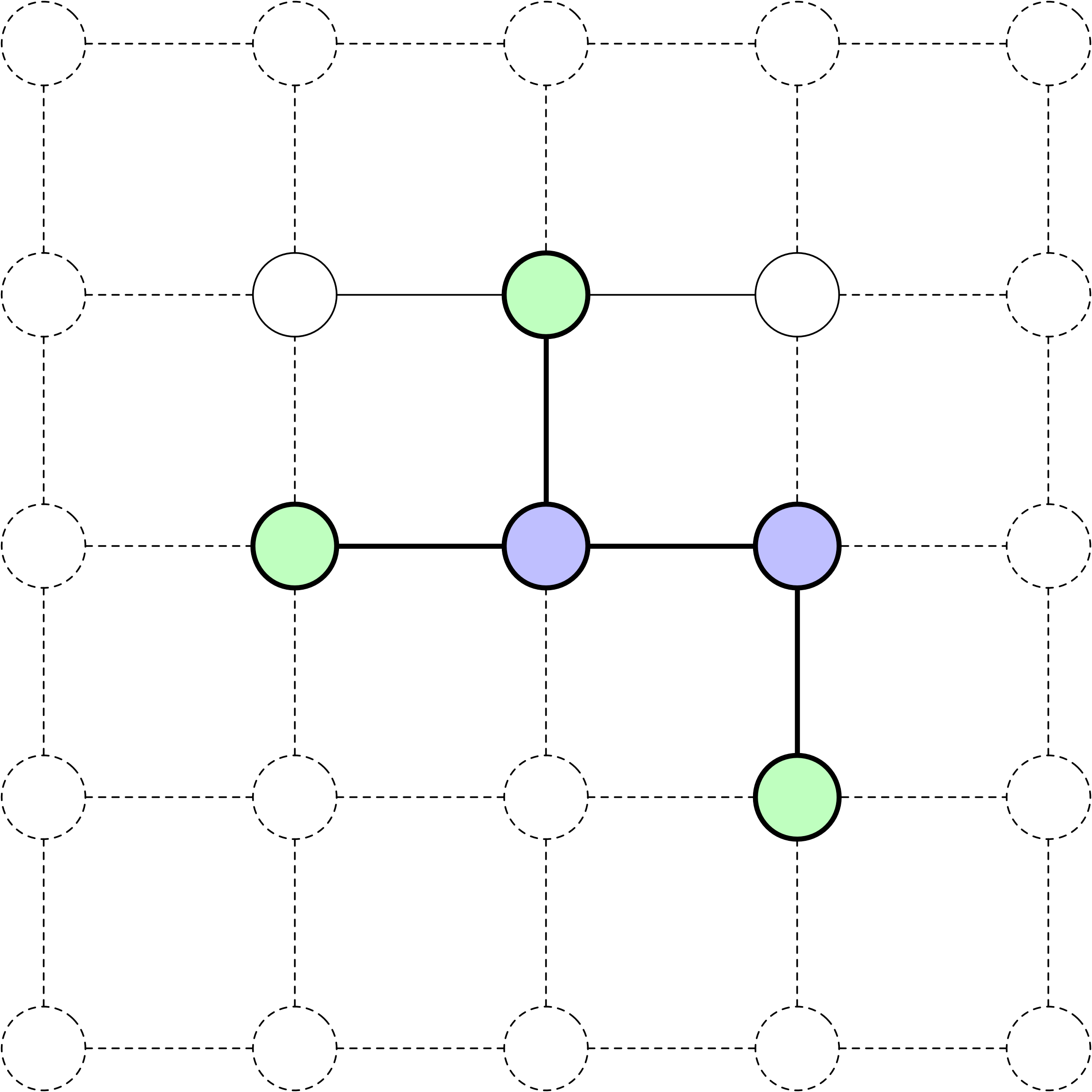

Frontière
is_empty
is_goal
expand
def expand(state):
"""Génère les états successeurs en déplaçant la tuile vide dans toutes les directions possibles."""
size = int(len(state) ** 0.5) # Déterminer la taille du puzzle (3 pour le 8-Puzzle, 4 pour le 15-Puzzle)
idx = state.index(0) # Trouver l'index de la tuile vide représentée par 0
x, y = idx % size, idx // size # Convertir l'index en coordonnées (x, y)
neighbors = []
# Définir les mouvements possibles : Gauche, Droite, Haut, Bas
moves = [(-1, 0), (1, 0), (0, -1), (0, 1)]
for dx, dy in moves:
nx, ny = x + dx, y + dy
# Vérifier si la nouvelle position est dans les limites du puzzle
if 0 <= nx < size and 0 <= ny < size:
n_idx = ny * size + nx
new_state = state.copy()
# Échanger la tuile vide avec la tuile adjacente
new_state[idx], new_state[n_idx] = new_state[n_idx], new_state[idx]
neighbors.append(new_state)
return neighborsprint_solution
def print_solution(solution):
"""Affiche la séquence d'étapes de l'état initial à l'état objectif."""
size = int(len(solution[0]) ** 0.5)
for step, state in enumerate(solution):
print(f"Étape {step} :")
for i in range(size):
row = state[i*size:(i+1)*size]
print(' '.join(str(n) if n != 0 else ' ' for n in row))
print()Recherche en largeur
La recherche en largeur (BFS) utilise une file d’attente pour gérer les nœuds de la frontière, également connus sous le nom de liste ouverte.
Recherche en largeur
def bfs(initial_state, goal_state):
frontier = deque() # Initialiser la file d'attente pour BFS
frontier.append((initial_state, [])) # Chaque élément est un tuple : (état, chemin)
explored = set()
explored.add(tuple(initial_state))
iterations = 0 # utilisé simplement pour comparer les algorithmes
while not is_empty(frontier):
current_state, path = frontier.popleft()
if is_goal(current_state, goal_state):
print(f"Nombre d'itérations : {iterations}")
return path + [current_state] # Retourner le chemin réussi
iterations = iterations + 1
for neighbor in expand(current_state):
neighbor_tuple = tuple(neighbor)
if neighbor_tuple not in explored:
explored.add(neighbor_tuple)
frontier.append((neighbor, path + [current_state]))
return None # Aucune solution trouvéeRecherche en profondeur
def dfs(initial_state, goal_state):
frontier = [(initial_state, [])] # Chaque élément est un tuple : (état, chemin)
explored = set()
explored.add(tuple(initial_state))
iterations = 0
while not is_empty(frontier):
current_state, path = frontier.pop()
if is_goal(current_state, goal_state):
print(f"Nombre d'itérations : {iterations}")
return path + [current_state] # Retourner le chemin réussi
iterations = iterations + 1
for neighbor in expand(current_state):
neighbor_tuple = tuple(neighbor)
if neighbor_tuple not in explored:
explored.add(neighbor_tuple)
frontier.append((neighbor, path + [current_state]))
return None # Aucune solution trouvéeRemarques
La recherche en largeur (BFS) identifie la solution optimale, 25 mouvements, en 145 605 itérations.
La recherche en profondeur (DFS) découvre une solution impliquant 1 157 mouvements en 1 187 itérations.
Recherche informée
Recherche heuristique
Les algorithmes de recherche informée utilisent des connaissances spécifiques au domaine concernant l’emplacement de l’état objectif.
Recherche heuristique
Soit \(f(n)\) une fonction heuristique qui estime le coût du chemin de moindre coût de l’état ou du nœud actuel \(n\) jusqu’à l’objectif.
Recherche heuristique
Dans les problèmes de recherche de route, on pourrait utiliser la distance en ligne droite du nœud actuel à la destination comme heuristique. Bien qu’un chemin réel puisse ne pas exister le long de cette ligne droite, l’algorithme donnera la priorité à l’expansion du nœud le plus proche de la destination (objectif) en se basant sur cette mesure en ligne droite.
Implémentation
Comment peut-on modifier les algorithmes existants de recherche en largeur et de recherche en profondeur pour implémenter la recherche du meilleur d’abord ?
- Cela peut être réalisé en utilisant une file de priorité, qui est triée selon les valeurs de la fonction heuristique \(f(n)\).
Observation
La recherche en largeur peut être interprétée comme une forme de recherche du meilleur d’abord, où la fonction heuristique \(f(n)\) est définie comme la profondeur du nœud dans l’arbre de recherche, correspondant à la longueur du chemin.
\(A^\star\)
\(A^\star\) (a-star) est la recherche informée la plus courante.
\[ f(n) = g(n) + h(n) \]
où
- \(g(n)\) est le coût du chemin depuis l’état initial jusqu’à \(n\).
- \(h(n)\) est une estimation du coût du plus court chemin de \(n\) à l’état final.
Admissibilité
Une heuristique est admissible si elle ne surestime jamais le coût réel pour atteindre l’objectif à partir de n’importe quel nœud dans l’espace de recherche.
Cela garantit que l’algorithme \(A^\star\) trouve une solution optimale, puisque le coût estimé est toujours une borne inférieure du coût réel.
Admissibilité
Formellement, une heuristique \(h(n)\) est admissible si : \[ h(n) \leq h^*(n) \] où :
- \(h(n)\) est l’estimation heuristique du coût depuis le nœud \(n\) jusqu’à l’objectif.
- \(h^*(n)\) est le coût réel du chemin optimal depuis le nœud \(n\) jusqu’à l’objectif.
Optimalité de coût
L’optimalité de coût se réfère à la capacité d’un algorithme à trouver la solution de moindre coût parmi toutes les solutions possibles. Dans le contexte des algorithmes de recherche comme \(A^\star\), l’optimalité de coût signifie que l’algorithme identifiera le chemin avec le coût total le plus bas depuis le départ jusqu’à l’objectif, à condition qu’une heuristique admissible soit utilisée.
Preuve d’optimalité
Théorème : Si \(h(n)\) est une heuristique admissible, alors \(A^\star\) utilisant \(h(n)\) trouvera toujours une solution optimale si elle existe.
Preuve :
Hypothèse par contradiction : Supposons que \(A^\star\) retourne une solution sous-optimale avec un coût \(C > C^\star\), où \(C^\star\) est le coût de la solution optimale.
État de la frontière : Au moment où \(A^\star\) trouve et retourne la solution sous-optimale, il ne doit y avoir aucun nœud inexploré \(n\) dans la frontière (liste ouverte) tel que \(f(n) \leq C^\star\). S’il existait un tel nœud, \(A^\star\) l’aurait sélectionné pour l’expansion avant le nœud menant à la solution sous-optimale en raison de sa valeur \(f(n)\) inférieure.
Existence de nœuds sur le chemin optimal : Cependant, le long du chemin optimal vers l’objectif, il doit y avoir des nœuds \(n\) tels que \(f(n) = g(n) + h(n) \leq C^\star\), car :
- \(g(n)\) est le coût du début à \(n\) le long du chemin optimal, donc \(g(n) \leq C^\star\).
- \(h(n) \leq h^*(n)\) parce que \(h(n)\) est admissible.
- \(h^*(n)\) est le coût réel de \(n\) à l’objectif le long du chemin optimal, donc \(g(n) + h^*(n) = C^\star\).
- Par conséquent, \(f(n) = g(n) + h(n) \leq g(n) + h^*(n) = C^\star\).
Contradiction : Cela signifie qu’il y a des nœuds dans la frontière avec \(f(n) \leq C^\star\) qui n’ont pas encore été explorés, ce qui contredit l’hypothèse qu’aucun de ces nœuds n’existe au moment où la solution sous-optimale est retournée.
Conclusion : Par conséquent, \(A^\star\) ne peut pas retourner une solution sous-optimale lorsqu’il utilise une heuristique admissible. Il doit trouver la solution optimale avec un coût \(C^\star\). C.Q.F.D.
8-Puzzle
Pouvez-vous penser à une fonction heuristique pour le casse-tête de 8 tuiles ?
Distance des tuiles mal placées
8-Puzzle
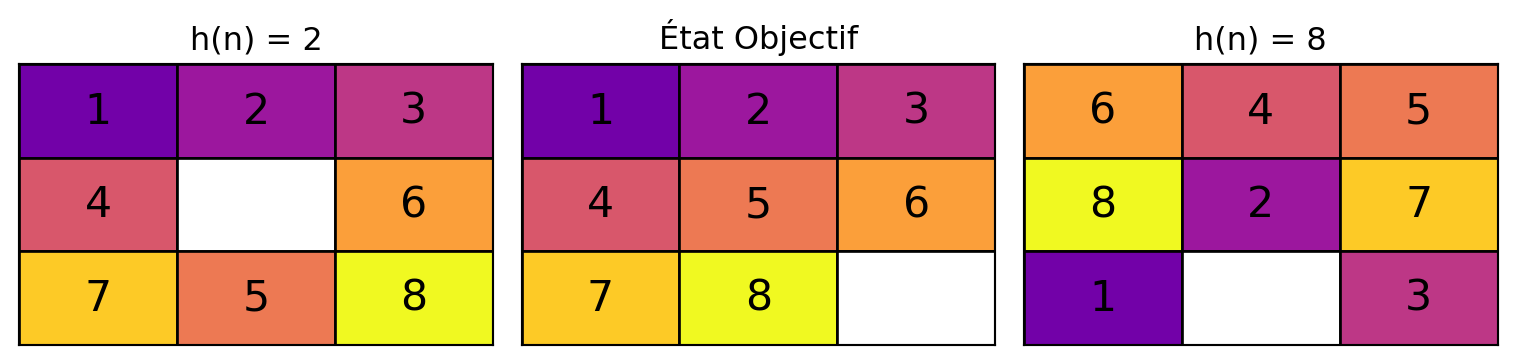
Recherche du meilleur d’abord
def best_first_search(initial_state, goal_state):
frontier = [] # Initialisez la file de priorité
initial_h = misplaced_tiles_distance(initial_state, goal_state)
# Ajoutez l'état initial avec sa valeur heuristique dans la file
heapq.heappush(frontier, (initial_h, 0, initial_state, [])) # (f(n), g(n), état, chemin)
explored = set()
iterations = 0
while not is_empty(frontier):
f, g, current_state, path = heapq.heappop(frontier)
if is_goal(current_state, goal_state):
print(f"Nombre d'itérations : {iterations}")
return path + [current_state] # Retournez le chemin réussi
iterations += 1
explored.add(tuple(current_state))
for neighbor in expand(current_state):
if tuple(neighbor) not in explored:
new_g = g + 1 # Incrémentez le coût du chemin
h = misplaced_tiles_distance(neighbor, goal_state)
new_f = new_g + h # Calculez le nouveau coût total
# Ajoutez l'état voisin dans la file de priorité
heapq.heappush(frontier, (new_f, new_g, neighbor, path + [current_state]))
explored.add(tuple(neighbor)) # Marquez le voisin comme exploré
return None # Aucune solution trouvéeCas simple
Nombre d'itérations : 2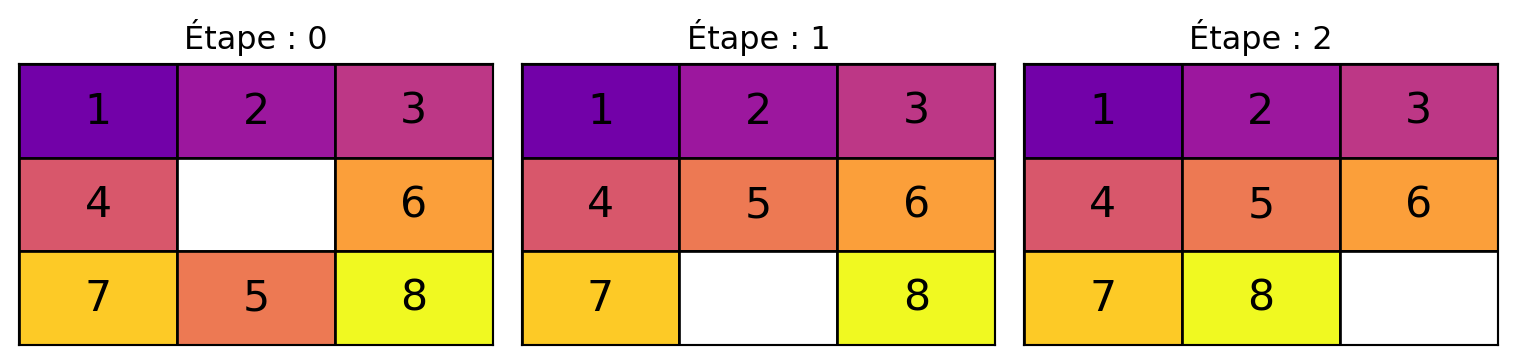
Cas difficile
initial_state_8 = [6, 4, 5,
8, 2, 7,
1, 0, 3]
goal_state_8 = [1, 2, 3,
4, 5, 6,
7, 8, 0]
print("Résolution du casse-tête de 8 tuiles avec best_first_search...")
solution_8_bfs = best_first_search(initial_state_8, goal_state_8)
if solution_8_bfs:
print(f"Solution trouvée par best_first_search en {len(solution_8_bfs) - 1} mouvements :")
print_solution(solution_8_bfs)
else:
print("Aucune solution trouvée pour le casse-tête de 8 tuiles avec best_first_search.")Résolution du casse-tête de 8 tuiles avec best_first_search...
Nombre d'itérations : 29005
Solution trouvée par best_first_search en 25 mouvements :
Étape 0 :
6 4 5
8 2 7
1 3
Étape 1 :
6 4 5
8 2 7
1 3
Étape 2 :
6 4 5
2 7
8 1 3
Étape 3 :
6 4 5
2 7
8 1 3
Étape 4 :
6 5
2 4 7
8 1 3
Étape 5 :
6 5
2 4 7
8 1 3
Étape 6 :
2 6 5
4 7
8 1 3
Étape 7 :
2 6 5
4 7
8 1 3
Étape 8 :
2 6 5
4 1 7
8 3
Étape 9 :
2 6 5
4 1 7
8 3
Étape 10 :
2 6 5
1 7
4 8 3
Étape 11 :
2 6 5
1 7
4 8 3
Étape 12 :
2 6 5
1 7
4 8 3
Étape 13 :
2 6 5
1 7 3
4 8
Étape 14 :
2 6 5
1 7 3
4 8
Étape 15 :
2 6 5
1 3
4 7 8
Étape 16 :
2 5
1 6 3
4 7 8
Étape 17 :
2 5
1 6 3
4 7 8
Étape 18 :
2 5 3
1 6
4 7 8
Étape 19 :
2 5 3
1 6
4 7 8
Étape 20 :
2 3
1 5 6
4 7 8
Étape 21 :
2 3
1 5 6
4 7 8
Étape 22 :
1 2 3
5 6
4 7 8
Étape 23 :
1 2 3
4 5 6
7 8
Étape 24 :
1 2 3
4 5 6
7 8
Étape 25 :
1 2 3
4 5 6
7 8
8-Puzzle
8-Puzzle
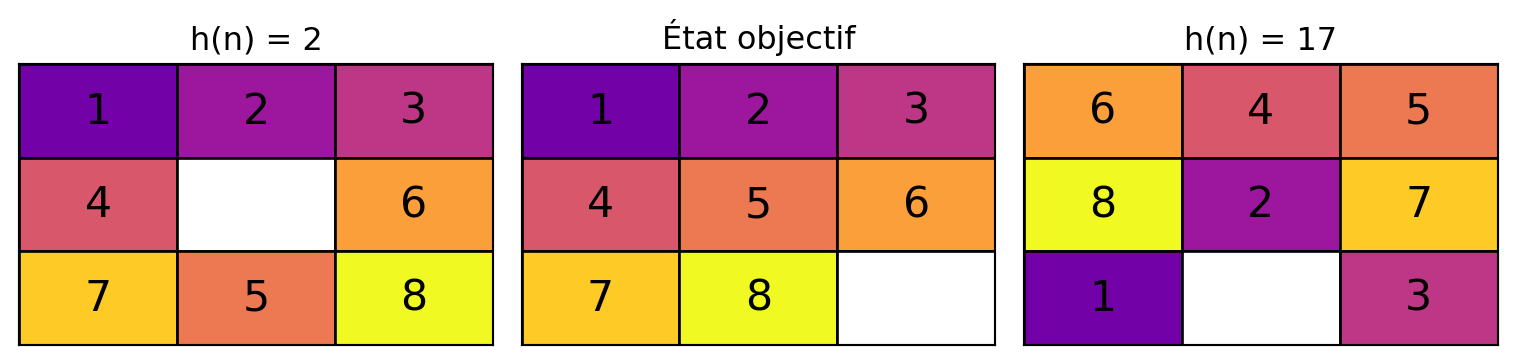
8-Puzzle
- Comparer les heuristiques Manhattan et Tuiles Mal Placées.
- Laquelle est la plus efficace ?
- Différences significatives de temps d’exécution ?
8-Puzzle
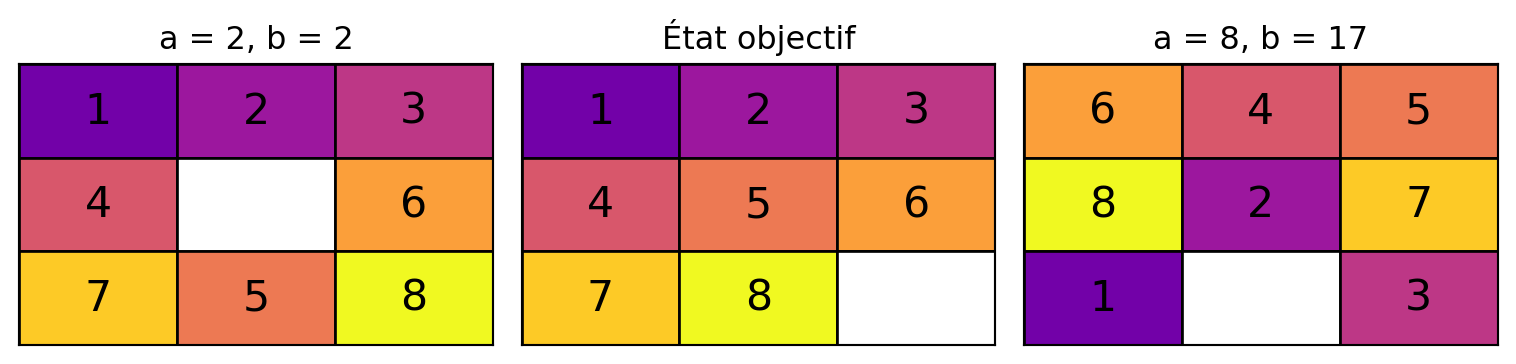
où
- a = distance des tuiles mal placées
- b = distance de Manathan
8-Puzzle
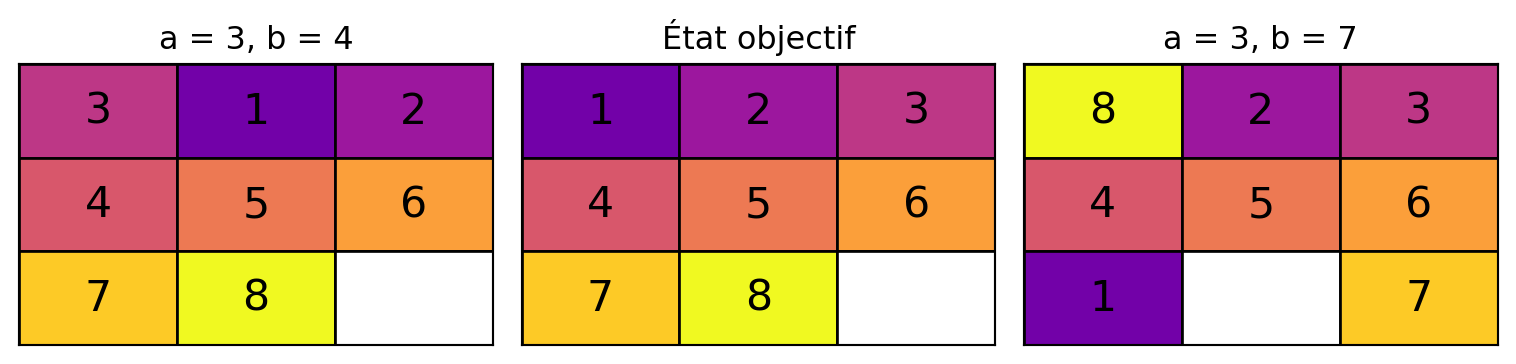
où
- a = distance des tuiles mal placées
- b = distance de Manhattan
Recherche du meilleur d’abord
def best_first_search_revised(initial_state, goal_state):
frontier = [] # Initialiser la file de priorité
initial_h = manhattan_distance(initial_state, goal_state)
# Ajouter l'état initial avec sa valeur heuristique dans la file
heapq.heappush(frontier, (initial_h, 0, initial_state, [])) # (f(n), g(n), état, chemin)
explored = set()
iterations = 0
while not is_empty(frontier):
f, g, current_state, path = heapq.heappop(frontier)
if is_goal(current_state, goal_state):
print(f"Nombre d'itérations : {iterations}")
return path + [current_state] # Retourner le chemin réussi
iterations = iterations + 1
explored.add(tuple(current_state))
for neighbor in expand(current_state):
if tuple(neighbor) not in explored:
new_g = g + 1 # Incrémenter le coût du chemin
h = manhattan_distance(neighbor, goal_state)
new_f = new_g + h # Calculer le nouveau coût total
# Ajouter l'état voisin dans la file de priorité
heapq.heappush(frontier, (new_f, new_g, neighbor, path + [current_state]))
explored.add(tuple(neighbor)) # Marquer le voisin comme exploré
return None # Aucune solution trouvéeCas simple
Nombre d'itérations : 2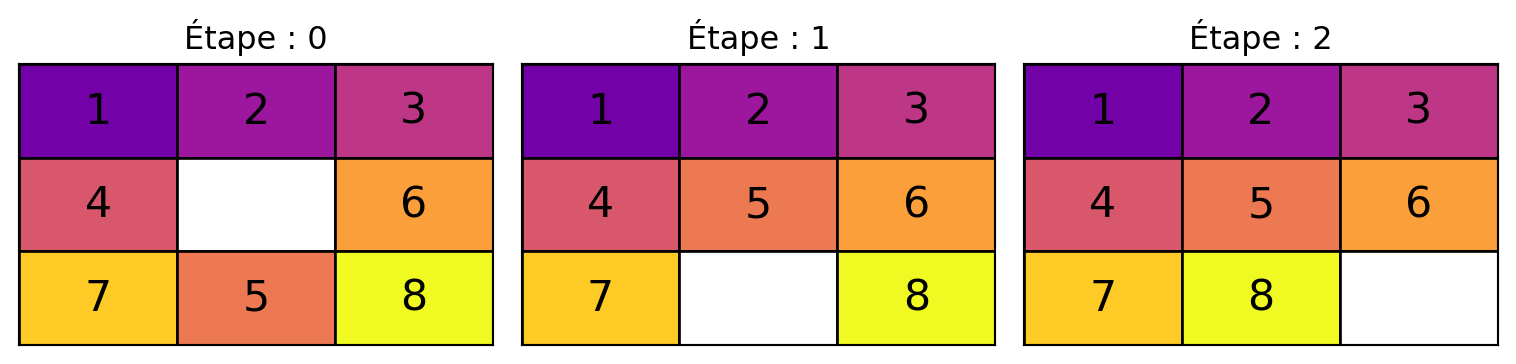
Cas difficile
initial_state_8 = [6, 4, 5,
8, 2, 7,
1, 0, 3]
goal_state_8 = [1, 2, 3,
4, 5, 6,
7, 8, 0]
print("Résolution du 8-Puzzle avec best_first_search...")
solution_8_bfs = best_first_search_revised(initial_state_8, goal_state_8)
if solution_8_bfs:
print(f"Solution best_first_search trouvée en {len(solution_8_bfs) - 1} mouvements :")
print_solution(solution_8_bfs)
else:
print("Aucune solution trouvée pour le 8-Puzzle en utilisant best_first_search.")Résolution du 8-Puzzle avec best_first_search...
Nombre d'itérations : 2255
Solution best_first_search trouvée en 25 mouvements :
Étape 0 :
6 4 5
8 2 7
1 3
Étape 1 :
6 4 5
8 2 7
1 3
Étape 2 :
6 4 5
2 7
8 1 3
Étape 3 :
6 4 5
2 7
8 1 3
Étape 4 :
6 5
2 4 7
8 1 3
Étape 5 :
6 5
2 4 7
8 1 3
Étape 6 :
2 6 5
4 7
8 1 3
Étape 7 :
2 6 5
4 7
8 1 3
Étape 8 :
2 6 5
4 1 7
8 3
Étape 9 :
2 6 5
4 1 7
8 3
Étape 10 :
2 6 5
1 7
4 8 3
Étape 11 :
2 6 5
1 7
4 8 3
Étape 12 :
2 6 5
1 7
4 8 3
Étape 13 :
2 6 5
1 7 3
4 8
Étape 14 :
2 6 5
1 7 3
4 8
Étape 15 :
2 6 5
1 3
4 7 8
Étape 16 :
2 5
1 6 3
4 7 8
Étape 17 :
2 5
1 6 3
4 7 8
Étape 18 :
2 5 3
1 6
4 7 8
Étape 19 :
2 5 3
1 6
4 7 8
Étape 20 :
2 3
1 5 6
4 7 8
Étape 21 :
2 3
1 5 6
4 7 8
Étape 22 :
1 2 3
5 6
4 7 8
Étape 23 :
1 2 3
4 5 6
7 8
Étape 24 :
1 2 3
4 5 6
7 8
Étape 25 :
1 2 3
4 5 6
7 8
1000 Expériences
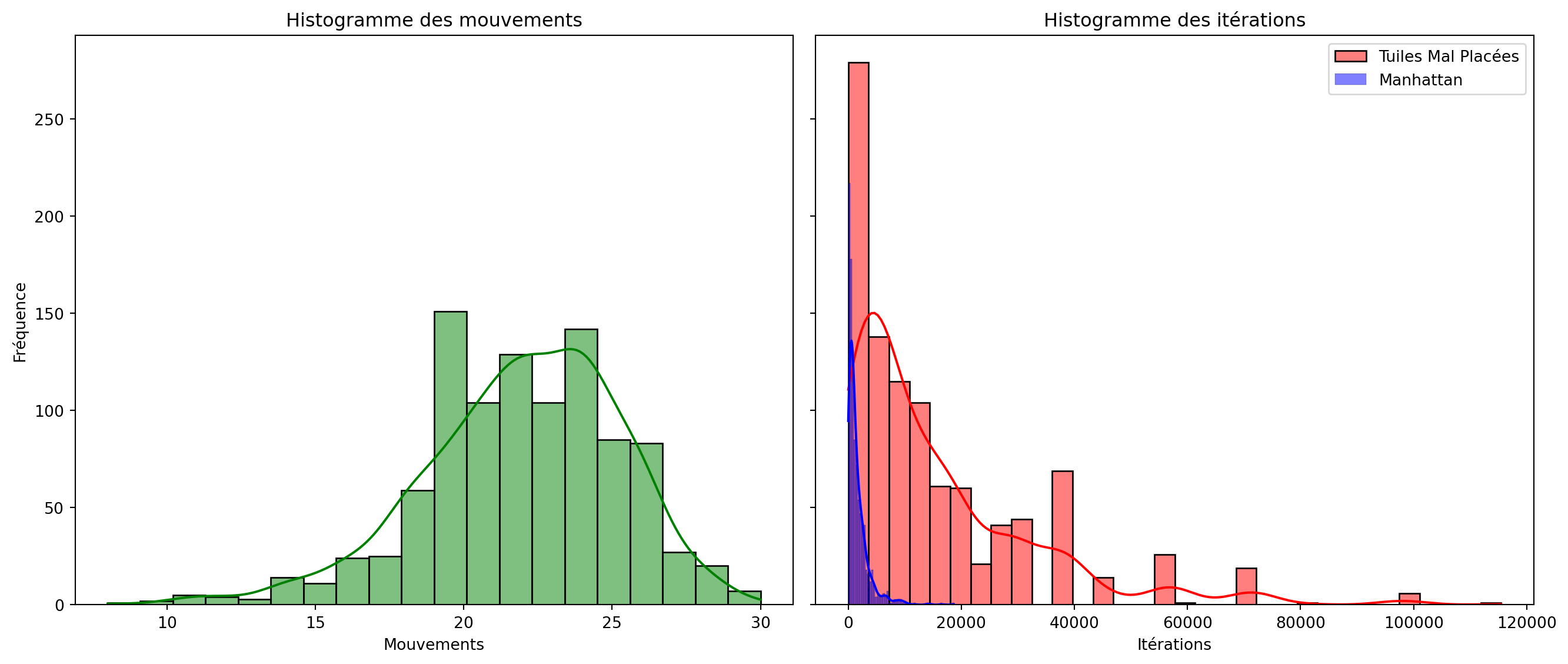
Diagramme de dispersion
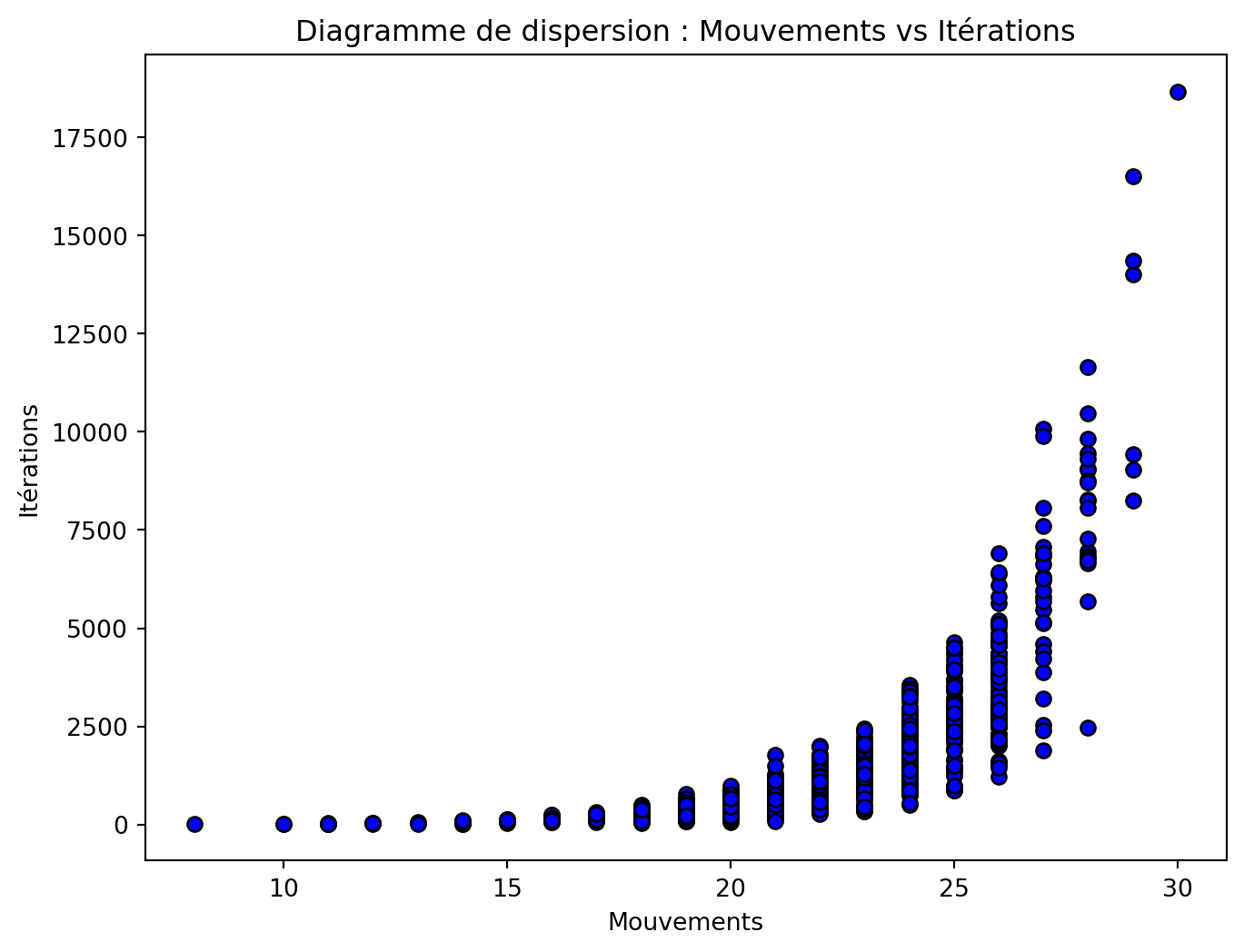
Exploration
La recherche en largeur (BFS) garantit de trouver le chemin le plus court, ou la solution de coût le plus bas, en supposant que toutes les actions ont un coût unitaire.
Développez un programme qui effectue les tâches suivantes :
- Générer une configuration aléatoire du puzzle 8-Puzzle.
- Déterminer le chemin le plus court en utilisant la recherche en largeur.
- Identifier la solution optimale en utilisant l’algorithme \(A^\star\).
- Comparer les coûts des solutions obtenues aux étapes 2 et 3. Il ne devrait pas y avoir de différence si \(A^\star\) identifie des solutions optimales en termes de coût.
- Répéter le processus.
Exploration
L’heuristique \(h(n) = 0\) est considérée comme admissible, mais elle entraîne généralement une exploration inefficace de l’espace de recherche. Développez un programme pour explorer ce concept. Montrez que, lorsque toutes les actions sont supposées avoir un coût unitaire, \(A^\star\) et la recherche en largeur (BFS) explorent l’espace de recherche de manière similaire. Plus précisément, ils examinent d’abord tous les chemins de longueur un, puis ceux de longueur deux, et ainsi de suite.
Remarques
La recherche en largeur (BFS) identifie la solution optimale, 25 mouvements, en 145 605 itérations.
La recherche en profondeur (DFS) découvre une solution impliquant 1 157 mouvements en 1 187 itérations.
La recherche du meilleur d’abord identifie la solution optimale, 25 mouvements, en 2 255 itérations.
Évaluation de la performance
Complétude : L’algorithme assure-t-il qu’une solution sera trouvée si elle existe et indique-t-il correctement l’absence de solution lorsqu’aucune solution n’existe ?
Optimalité du coût : L’algorithme identifie-t-il la solution avec le coût de chemin le plus bas parmi toutes les solutions possibles ?
Évaluation de la performance
Complexité temporelle : Comment le temps requis par l’algorithme évolue-t-il par rapport au nombre d’états et d’actions ?
Complexité spatiale : Comment l’espace requis par l’algorithme évolue-t-il par rapport au nombre d’états et d’actions ?
Vidéos par Sebastian Lague
- A* Pathfinding (E01 : explication de l’algorithme) publié le 2014-12-16.
- A* Pathfinding (E02 : grille de nœuds) publié le 2014-12-18.
- A* Pathfinding (E03 : implémentation de l’algorithme) publié le 2014-12-19.
- A* Pathfinding (E04 : optimisation du tas) publié le 2014-12-24.
- A* Pathfinding (E05 : unités) publié le 2015-01-06.
- A* Pathfinding (E06 : poids) publié le 2015-01-11.
- A* Pathfinding (E07 : poids lissés) publié le 2016-12-30.
- A* Pathfinding (E08 : lissage de chemin 1/2) publié le 2017-01-31.
- A* Pathfinding (E09 : lissage de chemin 2/2) publié le 2017-01-31.
- A* Pathfinding (E10 : threading) publié le 2017-02-03.
- Tutoriel A* Pathfinding (Unity) (liste de lecture)
Une ressource dédiée à \(A^\star\)
Prologue
Résumé
- Recherche informée et heuristiques
- Recherche du meilleur d’abord
- Implémentations
Prochaine conférence
- Nous explorerons plus en détail les fonctions heuristiques et examinerons d’autres algorithmes de recherche.
Références
Hart, Peter E., Nils J. Nilsson, et Bertram Raphael. 1968. « A Formal Basis for the Heuristic Determination of Minimum Cost Paths ». IEEE Transactions on Systems Science and Cybernetics 4 (2): 100‑107. https://doi.org/10.1109/tssc.1968.300136.
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.
Marcel Turcotte
École de science informatique et de génie électrique (SIGE)
Université d’Ottawa
