
Recherche locale
CSI 4106 - Automne 2024
Marcel Turcotte
Version: nov. 9, 2024 10h15
Préambule
Citation du jour
Objectifs d’apprentissage
- Comprendre le concept et l’application des algorithmes de recherche locale dans les problèmes d’optimisation.
- Implémenter et analyser l’algorithme de montée de colline (hill climbing), en reconnaissant ses limitations comme les maxima locaux et les plateaux.
- Appliquer des stratégies efficaces de représentation des états dans des problèmes comme les 8-Reines pour améliorer l’efficacité de la recherche.
- Expliquer comment le recuit simulé surmonte les optima locaux en acceptant probabilistiquement des états pires.
- Analyser l’influence de la température et de la différence d’énergie sur la probabilité d’acceptation dans le recuit simulé.
- Reconnaître l’application du recuit simulé dans la résolution de problèmes d’optimisation complexes comme le problème du voyageur de commerce.
Introduction
Contexte
- L’accent a été mis sur la recherche de chemins dans un espace d’états.
- Certains problèmes privilégient l’état final par rapport au chemin.
- Conception de circuits intégrés
- Ordonnancement d’atelier
- Programmation automatique
Problème des 8-Reines
Définition
Note
Les algorithmes de recherche locale opèrent en cherchant d’un état initial à des états voisins, sans tenir compte des chemins ni de l’ensemble des états atteints.
Définition du problème
Trouver l’état “meilleur” selon une fonction objectif, en localisant ainsi le maximum global.
Hill Climbing
Montée de colline (Hill Climbing)

Hill Climbing
Given as in input a problem
current is the initial state of problem
while not done do
- nighbour is the highest-valued successor state of current
- if value(neighbour) \(\le\) value(current) the return current
- set current to neighbour
8-Reines
Comment représenteriez-vous l’état courant?
Pourquoi l’utilisation d’une grille pour représenter l’état courant est-elle sous-optimale?
Une représentation en grille permet le placement illégal de reines dans la même colonne.
À la place, nous pouvons représenter l’état comme une liste (\(\mathrm{état}\)), où chaque élément correspond à la position de la ligne de la reine dans sa colonne respective.
En d’autres termes, \(\mathrm{état}[i]\) est la ligne de la reine dans la colonne \(i\).
Représentation de l’état

create_initial_state
create_initial_state

Représentation des 8-Reines
Échiquier \(8 \times 8\).
Placement sans contrainte : \(\binom{64}{8} = 4,426,165,368\) configurations possibles, représentant la sélection de 8 cases parmi 64.
Contrainte de colonne : Utilisez une liste de longueur 8, chaque entrée indiquant la ligne d’une reine dans sa colonne respective, ce qui donne \(8^8 = 16,777,216\) configurations.
Contraintes de ligne et de colonne : Modélisez les états du plateau comme des permutations des indices de ligne des 8 reines, réduisant les configurations à \(8! = 40,320\).
create_initial_state
create_initial_state

calculate_conflicts
def calculate_conflicts(etat):
n = len(etat)
conflits = 0
for col_i in range(n):
for col_j in range(col_i + 1, n):
row_i = etat[col_i]
row_j = etat[col_j]
if row_i == row_j: # même ligne
conflits += 1
if col_i - row_i == col_j - row_j: # même diagonale
conflits += 1
if col_i + row_i == col_j + row_j: # même antidiagonale
conflits += 1
return conflitscalculate_conflicts

get_neighbors_rn
def get_neighbors_rn(etat):
"""Génère des états voisins en déplaçant une reine à la fois vers une nouvelle ligne."""
voisins = []
n = len(etat)
for col in range(n):
for row in range(n):
if (etat[col] != row):
nouvel_etat = etat[:] # copie de l'état
nouvel_etat[col] = row
voisins.append(nouvel_etat)
return voisinsget_neighbors_rn
initial_state_8 = create_initial_state(8)
print(initial_state_8)
for s in get_neighbors_rn(initial_state_8):
print(f"{s} -> # of conflicts = {calculate_conflicts(s)}")[3, 2, 7, 1, 6, 0, 4, 5]
[0, 2, 7, 1, 6, 0, 4, 5] -> # of conflicts = 5
[1, 2, 7, 1, 6, 0, 4, 5] -> # of conflicts = 6
[2, 2, 7, 1, 6, 0, 4, 5] -> # of conflicts = 6
[4, 2, 7, 1, 6, 0, 4, 5] -> # of conflicts = 6
[5, 2, 7, 1, 6, 0, 4, 5] -> # of conflicts = 7
[6, 2, 7, 1, 6, 0, 4, 5] -> # of conflicts = 5
[7, 2, 7, 1, 6, 0, 4, 5] -> # of conflicts = 5
[3, 0, 7, 1, 6, 0, 4, 5] -> # of conflicts = 5
[3, 1, 7, 1, 6, 0, 4, 5] -> # of conflicts = 5
[3, 3, 7, 1, 6, 0, 4, 5] -> # of conflicts = 7
[3, 4, 7, 1, 6, 0, 4, 5] -> # of conflicts = 7
[3, 5, 7, 1, 6, 0, 4, 5] -> # of conflicts = 5
[3, 6, 7, 1, 6, 0, 4, 5] -> # of conflicts = 6
[3, 7, 7, 1, 6, 0, 4, 5] -> # of conflicts = 5
[3, 2, 0, 1, 6, 0, 4, 5] -> # of conflicts = 9
[3, 2, 1, 1, 6, 0, 4, 5] -> # of conflicts = 8
[3, 2, 2, 1, 6, 0, 4, 5] -> # of conflicts = 7
[3, 2, 3, 1, 6, 0, 4, 5] -> # of conflicts = 8
[3, 2, 4, 1, 6, 0, 4, 5] -> # of conflicts = 7
[3, 2, 5, 1, 6, 0, 4, 5] -> # of conflicts = 7
[3, 2, 6, 1, 6, 0, 4, 5] -> # of conflicts = 6
[3, 2, 7, 0, 6, 0, 4, 5] -> # of conflicts = 6
[3, 2, 7, 2, 6, 0, 4, 5] -> # of conflicts = 5
[3, 2, 7, 3, 6, 0, 4, 5] -> # of conflicts = 4
[3, 2, 7, 4, 6, 0, 4, 5] -> # of conflicts = 5
[3, 2, 7, 5, 6, 0, 4, 5] -> # of conflicts = 5
[3, 2, 7, 6, 6, 0, 4, 5] -> # of conflicts = 6
[3, 2, 7, 7, 6, 0, 4, 5] -> # of conflicts = 6
[3, 2, 7, 1, 0, 0, 4, 5] -> # of conflicts = 6
[3, 2, 7, 1, 1, 0, 4, 5] -> # of conflicts = 6
[3, 2, 7, 1, 2, 0, 4, 5] -> # of conflicts = 8
[3, 2, 7, 1, 3, 0, 4, 5] -> # of conflicts = 5
[3, 2, 7, 1, 4, 0, 4, 5] -> # of conflicts = 5
[3, 2, 7, 1, 5, 0, 4, 5] -> # of conflicts = 7
[3, 2, 7, 1, 7, 0, 4, 5] -> # of conflicts = 6
[3, 2, 7, 1, 6, 1, 4, 5] -> # of conflicts = 6
[3, 2, 7, 1, 6, 2, 4, 5] -> # of conflicts = 6
[3, 2, 7, 1, 6, 3, 4, 5] -> # of conflicts = 9
[3, 2, 7, 1, 6, 4, 4, 5] -> # of conflicts = 7
[3, 2, 7, 1, 6, 5, 4, 5] -> # of conflicts = 8
[3, 2, 7, 1, 6, 6, 4, 5] -> # of conflicts = 7
[3, 2, 7, 1, 6, 7, 4, 5] -> # of conflicts = 8
[3, 2, 7, 1, 6, 0, 0, 5] -> # of conflicts = 3
[3, 2, 7, 1, 6, 0, 1, 5] -> # of conflicts = 4
[3, 2, 7, 1, 6, 0, 2, 5] -> # of conflicts = 3
[3, 2, 7, 1, 6, 0, 3, 5] -> # of conflicts = 4
[3, 2, 7, 1, 6, 0, 5, 5] -> # of conflicts = 3
[3, 2, 7, 1, 6, 0, 6, 5] -> # of conflicts = 4
[3, 2, 7, 1, 6, 0, 7, 5] -> # of conflicts = 4
[3, 2, 7, 1, 6, 0, 4, 0] -> # of conflicts = 4
[3, 2, 7, 1, 6, 0, 4, 1] -> # of conflicts = 4
[3, 2, 7, 1, 6, 0, 4, 2] -> # of conflicts = 6
[3, 2, 7, 1, 6, 0, 4, 3] -> # of conflicts = 6
[3, 2, 7, 1, 6, 0, 4, 4] -> # of conflicts = 4
[3, 2, 7, 1, 6, 0, 4, 6] -> # of conflicts = 4
[3, 2, 7, 1, 6, 0, 4, 7] -> # of conflicts = 4get_neighbors
get_neighbors
print(initial_state_8)
for s in get_neighbors(initial_state_8):
print(f"{s} -> # of conflicts = {calculate_conflicts(s)}")[3, 2, 7, 1, 6, 0, 4, 5]
[2, 3, 7, 1, 6, 0, 4, 5] -> # of conflicts = 8
[7, 2, 3, 1, 6, 0, 4, 5] -> # of conflicts = 6
[1, 2, 7, 3, 6, 0, 4, 5] -> # of conflicts = 3
[6, 2, 7, 1, 3, 0, 4, 5] -> # of conflicts = 3
[0, 2, 7, 1, 6, 3, 4, 5] -> # of conflicts = 7
[4, 2, 7, 1, 6, 0, 3, 5] -> # of conflicts = 3
[5, 2, 7, 1, 6, 0, 4, 3] -> # of conflicts = 6
[3, 7, 2, 1, 6, 0, 4, 5] -> # of conflicts = 5
[3, 1, 7, 2, 6, 0, 4, 5] -> # of conflicts = 3
[3, 6, 7, 1, 2, 0, 4, 5] -> # of conflicts = 7
[3, 0, 7, 1, 6, 2, 4, 5] -> # of conflicts = 4
[3, 4, 7, 1, 6, 0, 2, 5] -> # of conflicts = 3
[3, 5, 7, 1, 6, 0, 4, 2] -> # of conflicts = 4
[3, 2, 1, 7, 6, 0, 4, 5] -> # of conflicts = 7
[3, 2, 6, 1, 7, 0, 4, 5] -> # of conflicts = 5
[3, 2, 0, 1, 6, 7, 4, 5] -> # of conflicts = 10
[3, 2, 4, 1, 6, 0, 7, 5] -> # of conflicts = 4
[3, 2, 5, 1, 6, 0, 4, 7] -> # of conflicts = 4
[3, 2, 7, 6, 1, 0, 4, 5] -> # of conflicts = 5
[3, 2, 7, 0, 6, 1, 4, 5] -> # of conflicts = 5
[3, 2, 7, 4, 6, 0, 1, 5] -> # of conflicts = 4
[3, 2, 7, 5, 6, 0, 4, 1] -> # of conflicts = 4
[3, 2, 7, 1, 0, 6, 4, 5] -> # of conflicts = 6
[3, 2, 7, 1, 4, 0, 6, 5] -> # of conflicts = 4
[3, 2, 7, 1, 5, 0, 4, 6] -> # of conflicts = 4
[3, 2, 7, 1, 6, 4, 0, 5] -> # of conflicts = 3
[3, 2, 7, 1, 6, 5, 4, 0] -> # of conflicts = 5
[3, 2, 7, 1, 6, 0, 5, 4] -> # of conflicts = 2hill_climbing
import numpy as np
def hill_climbing(etat_courant):
conflits_courants = calculate_conflicts(etat_courant)
while True:
if conflits_courants == 0:
return etat_courant
voisins = get_neighbors(etat_courant)
conflits = [calculate_conflicts(voisin) for voisin in voisins]
if (min(conflits)) > conflits_courants:
return None # Aucune amélioration trouvée, bloqué dans un minimum local
arg_best = np.argmin(conflits)
etat_courant = voisins[arg_best]
conflits_courants = conflits[arg_best]hill_climbing (version 2)
MAX_SIDE_MOVES = 100
def hill_climbing(etat_courant):
conflits_courants = calculate_conflicts(etat_courant)
mouvements_lateraux = 0
while True:
if conflits_courants == 0:
return etat_courant
voisins = get_neighbors(etat_courant)
conflits = [calculate_conflicts(voisin) for voisin in voisins]
if (min(conflits)) > conflits_courants:
return None # Aucune amélioration trouvée, bloqué dans un minimum local
if (min(conflits)) == conflits_courants:
mouvements_lateraux += 1 # Plateau
if mouvements_lateraux > MAX_SIDE_MOVES:
return None
arg_best = np.argmin(conflits)
etat_courant = voisins[arg_best]
conflits_courants = conflits[arg_best]Résoudre



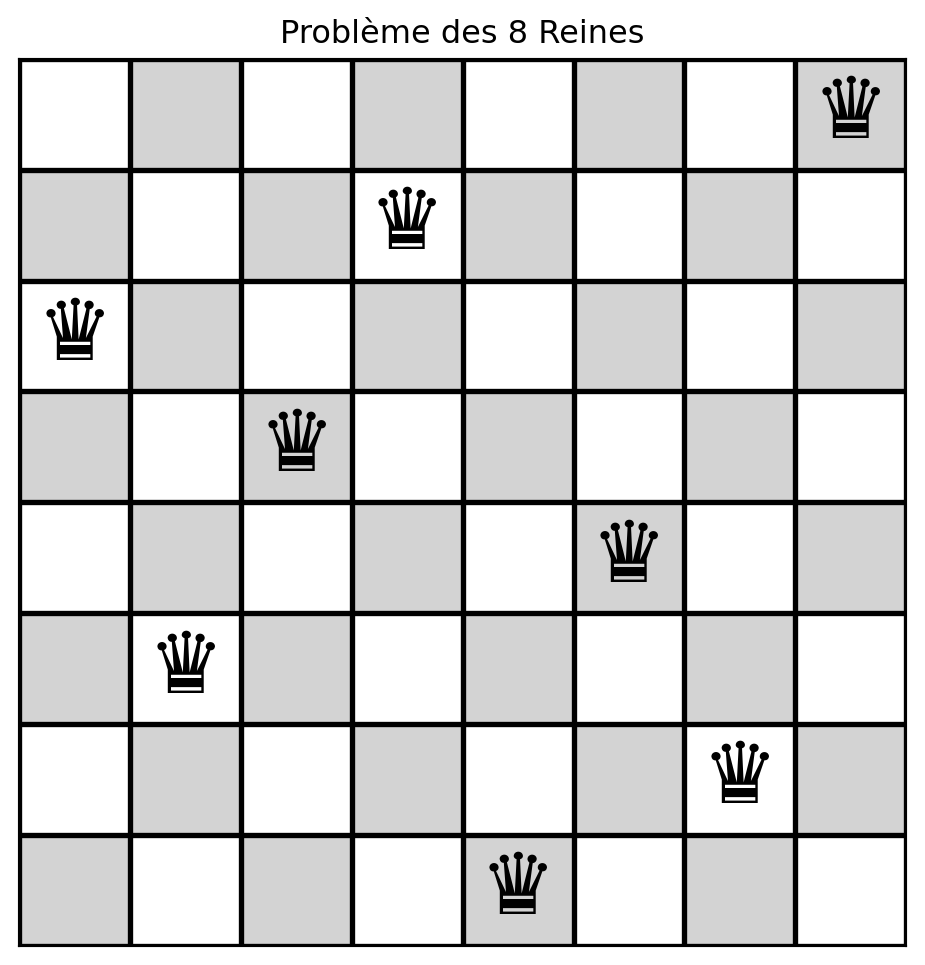





10 essais, nombre de solutions = 9, 0 déjà vuesRésoudre (2)
1000 essais, nombre de solutions = 704, 92 uniquesRésoudre 40-Reines
\(40! = 8.1591528325 \times 10^{47}\)
10 essais, nombre de solutions = 6, 6 uniques
Temps écoulé : 16.0282 secondes
Itérations et mouvement latéraux
1000 essais, nombre de solutions = 704, 92 uniques
20-Reines
1000 essais, nombre de solutions = 566, 566 uniques
Russell & Norvig
- La montée de colline échoue 86 % du temps.
- Les tentatives réussies nécessitent en moyenne 4 étapes pour une solution.
- Permettre 100 mouvements latéraux augmente le taux de réussite de 14 % à 94 %.
- L’espace de recherche contient \(8^8 = 16,777,216\) états.
- Implémentation de Russell & Norvig
Échapper à un optimum local
Quels mécanismes permettraient à l’algorithme de montée de colline d’échapper à un optimum local, qu’il s’agisse d’un minimum ou d’un maximum local ?
Remarque
Supposons que le problème d’optimisation soit une minimisation, où l’objectif est de trouver une solution avec le coût minimum.
Recuit simulé
Définition
Le recuit simulé (simulated annealing) est un algorithme d’optimisation inspiré du processus de recuit en métallurgie. Il explore l’espace de solutions de manière probabiliste en permettant des déplacements occasionnels vers le haut, ce qui aide à échapper aux optima locaux. L’algorithme réduit progressivement la probabilité d’accepter des solutions pires en diminuant un paramètre de “température”, convergeant ainsi vers une solution optimale ou quasi-optimale.
Recuit
Note
En métallurgie, le recuit est le processus de durcissement des métaux et du verre en les chauffant à haute température et en les refroidissant progressivement, permettant ainsi au matériau d’atteindre un état cristallin à faible énergie.
Algorithme

Variation de \(\Delta E\)

Variation de la température, \(T\)

Variation de la température et de \(\Delta E\)

Faire varier la température et \(\Delta E\)
import { Inputs, Plot } from "@observablehq/plot"
viewof deltaE = Inputs.range([0.01, 100], {step: 0.01, value: 0.1, label: "ΔE", width: 300})
T_values = Array.from({length: 1000}, (_, i) => (i + 1) * 0.1)
function computeData(deltaE) {
return T_values.map(T => ({
T: T,
value: Math.exp(-deltaE / T)
}))
}
data = computeData(deltaE)
Plot.plot({
marks: [
Plot.line(data, {
x: "T",
y: "value",
stroke: "steelblue",
strokeWidth: 2
}),
Plot.ruleX([0], {stroke: "black"}), // X-axis line
Plot.ruleY([0], {stroke: "black"}) // Y-axis line
]
})Théorie
Note
Si le calendrier abaisse \(T\) à 0 suffisamment lentement, une propriété de la distribution de Boltzmann (alias Gibbs), \(e^{\frac{\Delta E}{T}}\), est que toute la probabilité se concentre sur les maxima globaux, que l’algorithme trouvera avec une probabilité tendant vers 1.
Définition
Le problème du voyageur de commerce (travelling salesman problem) (TSP) est un problème d’optimisation classique qui cherche l’itinéraire le plus court possible pour un voyageur devant visiter un ensemble de villes, en revenant à la ville d’origine, tout en visitant chaque ville exactement une fois.
Calcul de la distance total
# Fonction pour calculer la distance totale d'un itinéraire donné
def calculate_total_distance(route, distance_matrix):
total_distance = 0
for i in range(len(route) - 1):
total_distance += distance_matrix[route[i], route[i + 1]]
total_distance += distance_matrix[route[-1], route[0]] # Retourner au point de départ
return total_distanceVoisinage
Comment générer une solution voisine?
Échanger deux villes
Description : Sélectionner deux villes au hasard et échanger leurs positions.
Avantages : Simple et efficace pour explorer des solutions voisines.
Inconvénients : Le changement peut être trop minime, ce qui peut ralentir la convergence.
Inverser le segment
Description : Sélectionner deux indices et inverser le segment entre eux.
Avantages : Plus efficace pour trouver des chemins plus courts par rapport aux échanges simples.
Inconvénients : Peut être coûteux en calcul à mesure que le nombre de villes augmente.
Supprimer & reconnecter
Description : Supprime trois arêtes de l’itinéraire et reconnecte les segments de la meilleure façon possible. Cela peut générer jusqu’à 7 itinéraires différents.
Avantages : Apporte des changements plus importants et peut échapper aux optima locaux plus efficacement.
Inconvénients : Plus complexe et coûteux en calcul à mettre en œuvre.
Mouvement d’insertion
Description : Sélectionner une ville et la déplacer à une position différente dans l’itinéraire.
Avantages : Offre un équilibre entre petits et grands changements, utile pour affiner les solutions.
Inconvénients : Peut nécessiter plus d’itérations pour converger vers une solution optimale.
Mélanger le sous-ensemble
Description : Sélectionner un sous-ensemble de villes dans l’itinéraire et mélanger leur ordre de manière aléatoire.
Avantages : Introduit des changements plus importants et peut aider à échapper aux minima locaux.
Inconvénients : Peut conduire à des itinéraires moins efficaces si mal géré.
Générer une solution voisine aléatoire
Recuit simulé
def simulated_annealing(distance_matrix, initial_temp, cooling_rate, max_iterations):
num_cities = len(distance_matrix)
current_route = np.arange(num_cities)
np.random.shuffle(current_route)
current_cost = calculate_total_distance(current_route, distance_matrix)
best_route = current_route.copy()
best_cost = current_cost
temperature = initial_temp
for iteration in range(max_iterations):
neighbor_route = get_neighbor(current_route)
neighbor_cost = calculate_total_distance(neighbor_route, distance_matrix)
# Accepter le voisin s'il est meilleur, ou avec une probabilité s'il est pire.
delta_E = neighbor_cost - current_cost
if neighbor_cost < current_cost or np.random.rand() < np.exp(-(delta_E)/temperature):
current_route = neighbor_route
current_cost = neighbor_cost
if current_cost < best_cost:
best_route = current_route.copy()
best_cost = current_cost
# Refroidir la température
temperature *= cooling_rate
return best_route, best_cost, temperatures, costsRemarques
- Lorsque \(t \to \infty\), l’algorithme présente un comportement caractéristique d’une marche aléatoire (random walk). Pendant cette phase, tout état voisin, qu’il améliore ou non la fonction objectif, est accepté. Cela facilite l’exploration et se produit au début de l’exécution de l’algorithme.
Remarques
- À l’inverse, lorsque \(t \to 0\), l’algorithme se comporte comme une montée de colline (hill climbing). Dans cette phase, seuls les états qui améliorent la valeur de la fonction objectif sont acceptés, garantissant que l’algorithme se dirige systématiquement vers des solutions optimales — spécifiquement, vers des valeurs plus basses dans les problèmes de minimisation. Cette phase met l’accent sur l’exploitation des solutions prometteuses et se produit vers la fin de l’algorithme.
Exemple
# On s'assure de toujours générer les mêmes coordonnées
np.random.seed(42)
# Générer des coordonnées aléatoires pour les villes
num_cities = 20
coordinates = np.random.rand(num_cities, 2) * 100
# Calculer la matrice des distances
distance_matrix = np.sqrt(((coordinates[:, np.newaxis] - coordinates[np.newaxis, :]) ** 2).sum(axis=2))
# Paramètres du recuit simulé
initial_temp = 15
cooling_rate = 0.995
max_iterations = 1000Algorithme de Held–Karp
- Introduction : 1962 par Held, Karp et indépendamment par Bellman.
- Problème : Résout le problème du voyageur de commerce (TSP) avec la programmation dynamique.
- Complexité temporelle : \(\Theta(2^n n^2)\).
- Complexité spatiale : \(\Theta(2^n n)\).
- Efficacité : Meilleur que la méthode exhaustive \(\Theta(n!)\), mais reste exponentiel.
Held–Karp pour trouver le coût minimum: 386.43Trace d’exécution

Meilleur itinéraire

Température et coût

Échange de voisins
Description : Sélectionner deux villes au hasard et échanger leurs positions.
Avantages : Simple et efficace pour explorer des solutions voisines.
Inconvénients : Le changement peut être trop minime, ce qui peut ralentir la convergence.
Trace d’exécution

Meilleur chemin

Température et coût

Sélection d’une stratégie de voisinage
Mouvements simples (échange, insertion) : Efficaces pour l’exploration initiale ; risque d’être piégé dans des optima locaux.
Mouvements complexes : Améliorent la capacité à échapper aux optima locaux et accélèrent la convergence ; impliquent un coût computationnel plus élevé.
Approches hybrides : Intégrer diverses stratégies pour la génération de voisinage. Utiliser des mouvements simples au début, en passant à des mouvements complexes à mesure que la convergence progresse.
Température initiale
Influence : Étant donné que la probabilité d’accepter un nouvel état est donnée par \(e^{-\frac{\Delta E}{T}}\), la sélection de la température initiale est directement influencée par \(\Delta E\) et donc par la valeur de la fonction objectif pour un état aléatoire, \(f(s)\).
Température initiale
Problèmes exemple : Considérons deux scénarios : le problème \(a\) avec \(f(a) = 1,000\) et le problème \(b\) avec \(f(b) = 100\).
Différence d’énergie : Accepter un état 10 % pire entraîne des différences d’énergie de \(\Delta E = 0.1 \cdot f(a) = 100\) pour le problème \(a\) et \(\Delta E = 0.1 \cdot f(b) = 10\) pour le problème \(b\).
Probabilité d’acceptation : Pour accepter un tel état 60 % du temps, on fixe \(e^{-\frac{\Delta E}{T}} = 0.6\). La résolution pour \(T\) donne des températures initiales d’environ \(T \approx 195.8\) pour le problème \(a\) et \(T \approx 19.58\) pour le problème \(b\).
Température initiale
Une approche populaire consiste à définir la température initiale de sorte qu’une portion significative des mouvements (souvent autour de 60-80%) soit acceptée.
Cela peut être réalisé en exécutant une phase préliminaire où la température est ajustée jusqu’à ce que le ratio d’acceptation se stabilise dans cette plage.
Stratégies de refroidissement
Dans le cadre du recuit simulé, le refroidissement est essentiel pour gérer la convergence de l’algorithme. Le calendrier de refroidissement détermine le taux de diminution de la température, influençant ainsi la capacité de l’algorithme à échapper aux optima locaux et à converger vers une solution quasi-optimale.
Refroidissement linéaire
- Description : La température diminue linéairement à chaque itération.
- Formule : \(T = T_0 - \alpha \cdot k\)
- \(T_0\) : Température initiale
- \(\alpha\) : Un décrément constant
- \(k\) : Itération actuelle
- Avantages : Simple à mettre en œuvre et à comprendre.
- Inconvénients : Conduit souvent à une convergence prématurée car la température diminue trop rapidement.
Refroidissement géométrique
- Description : La température diminue de manière exponentielle à chaque itération.
- Formule : \(T = T_0 \cdot \alpha^k\)
- \(\alpha\) : Taux de refroidissement, généralement entre 0,8 et 0,99
- \(k\) : Itération actuelle
- Avantages : Largement utilisé pour sa simplicité et son efficacité.
- Inconvénients : Le choix de \(\alpha\) est crucial ; s’il est trop petit, la température baisse trop rapidement, et s’il est trop grand, la convergence peut être lente.
Refroidissement logarithmique
- Description : La température diminue lentement selon une fonction logarithmique.
- Formule : \(T = \frac{\alpha \cdot T_0}{\log(1+k)}\)
- \(\alpha\) : Une constante de mise à l’échelle
- \(k\) : Itération actuelle
- Avantages : Offre un taux de refroidissement plus lent, utile pour les problèmes nécessitant une exploration approfondie de l’espace de solution.
- Inconvénients : La convergence peut être très lente, nécessitant de nombreuses itérations.
Refroidissement inverse
- Description : La température diminue selon une fonction inverse du numéro d’itération.
- Formule : \(T = \frac{T_0}{1+\alpha \cdot k}\)
- \(\alpha\) : Une constante de mise à l’échelle
- \(k\) : Itération actuelle
- Avantages : Permet un processus de refroidissement plus contrôlé, équilibrant exploration et exploitation.
- Inconvénients : Peut nécessiter un ajustement minutieux de \(\alpha\) pour être efficace.
Refroidissement adaptatif
- Description : Le calendrier de refroidissement est ajusté dynamiquement en fonction des performances de l’algorithme.
- Stratégie : Si l’algorithme ne progresse pas de manière significative, le taux de refroidissement peut être ralenti. Inversement, si le progrès est régulier, le taux de refroidissement peut être accéléré.
- Avantages : Plus flexible et peut s’adapter aux caractéristiques du problème.
- Inconvénients : Plus complexe à mettre en œuvre et nécessite une conception minutieuse pour éviter l’instabilité.
Stratégies de refroidissement

Choisir la bonne stratégie
Spécifique au problème : Le choix du calendrier de refroidissement dépend souvent des caractéristiques du problème à résoudre. Certains problèmes bénéficient d’un taux de refroidissement plus lent, tandis que d’autres peuvent nécessiter une convergence plus rapide.
Expérimentation : Il est courant d’expérimenter différentes stratégies et paramètres pour trouver le meilleur équilibre entre exploration (recherche large) et exploitation (affinement des meilleures solutions actuelles).
Conclusion
Après l’application du recuit simulé, une méthode de recherche locale comme la montée de colline peut être utilisée pour affiner la solution.
Le recuit simulé est efficace pour explorer l’espace de solutions et éviter les minima locaux, tandis que la recherche locale se concentre sur l’exploration des solutions voisines de celle obtenue.
Visualisation du recuit simulé
Prologue
Résumé
- Les algorithmes de recherche locale se concentrent sur la recherche d’états objectifs en se déplaçant entre des états voisins sans suivre les chemins.
- L’algorithme de montée de colline recherche le voisin de plus grande valeur mais peut se retrouver coincé dans des maxima locaux ou des plateaux.
- Une représentation efficace de l’état, comme l’utilisation de permutations dans le problème des 8-Reines, évite les placements illégaux et améliore les performances.
- Le recuit simulé permet des déplacements occasionnels vers le haut pour échapper aux optima locaux, contrôlés par un paramètre de température décroissant.
- La probabilité d’acceptation dans le recuit simulé diminue à mesure que la température baisse et que la différence d’énergie augmente.
- Le recuit simulé résout efficacement des problèmes complexes comme le problème du voyageur de commerce en explorant l’espace des solutions de manière probabiliste.
Lectures complémentaires

“La méthodologie globale du recuit simulé [simulated annealing] est ensuite déployée en détail sur une application réelle : un problème de planification de trajectoire aérienne à grande échelle impliquant près de 30 000 vols à l’échelle continentale européenne.”
Prochain cours
- Nous discuterons des algorithmes basés sur la population.
Références
Alex, Kwaku Peprah, Kojo Appiah Simon, et Kwame Amponsah Samuel. 2017. « An Optimal Cooling Schedule Using a Simulated Annealing Based Approach ». Applied Mathematics 08 (08): 1195‑1210. https://doi.org/10.4236/am.2017.88090.
Bellman, Richard. 1962. « Dynamic Programming Treatment of the Travelling Salesman Problem ». Journal of the ACM (JACM) 9 (1): 61‑63. https://doi.org/10.1145/321105.321111.
Ben-Ameur, Walid. 2004. « Computing the Initial Temperature of Simulated Annealing ». Computational Optimization and Applications 29 (3): 369‑85. https://doi.org/10.1023/b:coap.0000044187.23143.bd.
Gendreau, M., et J. Y. Potvin. 2019. Handbook of Metaheuristics. International Series in Operations Research & Management Science. Springer International Publishing. https://books.google.com.ag/books?id=RbfFwQEACAAJ.
Held, Michael, et Richard M. Karp. 1962. « A Dynamic Programming Approach to Sequencing Problems ». Journal of the Society for Industrial and Applied Mathematics 10 (1): 196‑210. https://doi.org/10.1137/0110015.
Nourani, Yaghout, et Bjarne Andresen. 1998. « A comparison of simulated annealing cooling strategies ». Journal of Physics A: Mathematical and General 31 (41): 8373.
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.
Prochain cours
- Nous discuterons des algorithmes basés sur les populations.
Références
Alex, Kwaku Peprah, Kojo Appiah Simon, et Kwame Amponsah Samuel. 2017. « An Optimal Cooling Schedule Using a Simulated Annealing Based Approach ». Applied Mathematics 08 (08): 1195‑1210. https://doi.org/10.4236/am.2017.88090.
Bellman, Richard. 1962. « Dynamic Programming Treatment of the Travelling Salesman Problem ». Journal of the ACM (JACM) 9 (1): 61‑63. https://doi.org/10.1145/321105.321111.
Ben-Ameur, Walid. 2004. « Computing the Initial Temperature of Simulated Annealing ». Computational Optimization and Applications 29 (3): 369‑85. https://doi.org/10.1023/b:coap.0000044187.23143.bd.
Gendreau, M., et J. Y. Potvin. 2019. Handbook of Metaheuristics. International Series in Operations Research & Management Science. Springer International Publishing. https://books.google.com.ag/books?id=RbfFwQEACAAJ.
Held, Michael, et Richard M. Karp. 1962. « A Dynamic Programming Approach to Sequencing Problems ». Journal of the Society for Industrial and Applied Mathematics 10 (1): 196‑210. https://doi.org/10.1137/0110015.
Nourani, Yaghout, et Bjarne Andresen. 1998. « A comparison of simulated annealing cooling strategies ». Journal of Physics A: Mathematical and General 31 (41): 8373.
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.
Marcel Turcotte
École de science informatique et de génie électrique (SIGE)
Université d’Ottawa

Comment représenter une solution?
Nous utiliserons une liste dans laquelle chaque élément représente l’indice d’une ville, et l’ordre des éléments indique la séquence de visite des villes.