Expliquer le concept et les étapes clés de la Recherche Arborescente de Monte-Carlo (MCTS).
Comparer MCTS avec d’autres algorithmes de recherche tels que BFS, DFS, A*, le Recuit Simulé et les Algorithmes Génétiques.
Analyser comment MCTS équilibre exploration et exploitation en utilisant la formule UCB1.
Implémenter MCTS dans des applications pratiques comme le Tic-Tac-Toe.
Introduction
Recherche Arborescente de Monte-Carlo (MCTS)
Dans le cours introductif sur la recherche dans l’espace d’états, j’ai utilisé la Recherche Arborescente de Monte-Carlo (MCTS), un élément clé d’AlphaGo, pour illustrer le rôle des algorithmes de recherche dans le raisonnement.
Aujourd’hui, nous concluons cette série en examinant les détails de l’implémentation de cet algorithme.
Applications
Conception de médicaments de novo
Routage de circuits électroniques
Surveillance de charge dans les réseaux intelligents
Maintien de voie et dépassement
Planification de mouvement dans la conduite autonome
Résolution du problème du voyageur de commerce
Notes Historiques
2008 : l’algorithme est introduit dans le contexte des jeux d’IA(Chaslot et al. 2008)
2016 : l’algorithme est combiné avec des réseaux neuronaux profonds pour créer AlphaGo(Silver et al. 2016)
Définition
Un algorithme de Monte-Carlo est une méthode computationnelle qui utilise l’échantillonnage aléatoire pour obtenir des résultats numériques, souvent utilisée pour l’optimisation, l’intégration numérique et l’estimation de distributions de probabilité.
Il se caractérise par sa capacité à traiter des problèmes complexes avec des solutions probabilistes, en échangeant l’exactitude contre l’efficacité et la scalabilité.
Algorithme
Sélection (parcours de l’arbre)
Expansion du nœud
Déroulement (rollout, simulation)
Rétropropagation (backpropagation)
Algorithme
Discussion
Comme d’autres algorithmes discutés précédemment, tels que BFS, DFS, et \(A^\star\), la Recherche Arborescente de Monte-Carlo (MCTS) maintient une frontière de nœuds non expansés.
Discussion
À l’instar de \(A^\star\), la Recherche Arborescente de Monte-Carlo (MCTS) utilise une heuristique, appelée politique, pour déterminer le nœud optimal à étendre.
Cependant, dans \(A^\star\), l’heuristique est généralement une fonction statique qui estime le coût pour atteindre un objectif, tandis que dans MCTS, la “politique” implique une évaluation dynamique.
Discussion
À l’instar du Recuit Simulé et des Algorithmes Génétiques, la Recherche Arborescente de Monte-Carlo (MCTS) intègre un mécanisme pour équilibrerexploration et exploitation.
Discussion
MCTS exploite tous les nœuds visités dans son processus de prise de décision, contrairement à \(A^\star\), qui se concentre principalement sur la frontière actuelle.
De plus, MCTS met à jour itérativement la valeur de ses nœuds en fonction des simulations, tandis que \(A^\star\) utilise généralement une heuristique statique.
Discussion
Contrairement aux algorithmes précédents avec des arbres de recherche implicites, MCTS construit une structure d’arbre explicite pendant l’exécution.
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Explication pas à pas
Russell et Norvig
Résumé (1)
Initialement, l’arbre possède un seul nœud, qui est \(S_0\).
Nous ajoutons ses descendants et nous sommes prêts à commencer.
La recherche d’arbre de Monte Carlo construit lentement son arbre de recherche.
Résumé (2)
À chaque itération, les étapes suivantes se produisent :
Sélection : Identifier le nœud optimal en parcourant un seul chemin dans l’arbre, guidé par UCB1.
Expansion : Élargir le nœud s’il est une feuille dans l’arbre MCTS, si \(n \gt 0\).
Déroulement : Simuler une partie depuis l’état actuel jusqu’à un état terminal en sélectionnant des actions aléatoirement.
Rétropropagation : Utiliser l’information obtenue pour mettre à jour le nœud actuel et tous les nœuds parents jusqu’à la racine.
Résumé (3)
Chaque nœud enregistre son score total et son nombre de visites.
Cette information est utilisée pour calculer une valeur qui guide le parcours de l’arbre, équilibrant exploration et exploitation.
Résumé (4)
\[
\mathrm{UCB1}(S_i) = \overline{V_i} + C \sqrt{\frac{\ln(N)}{n_i}}
\]
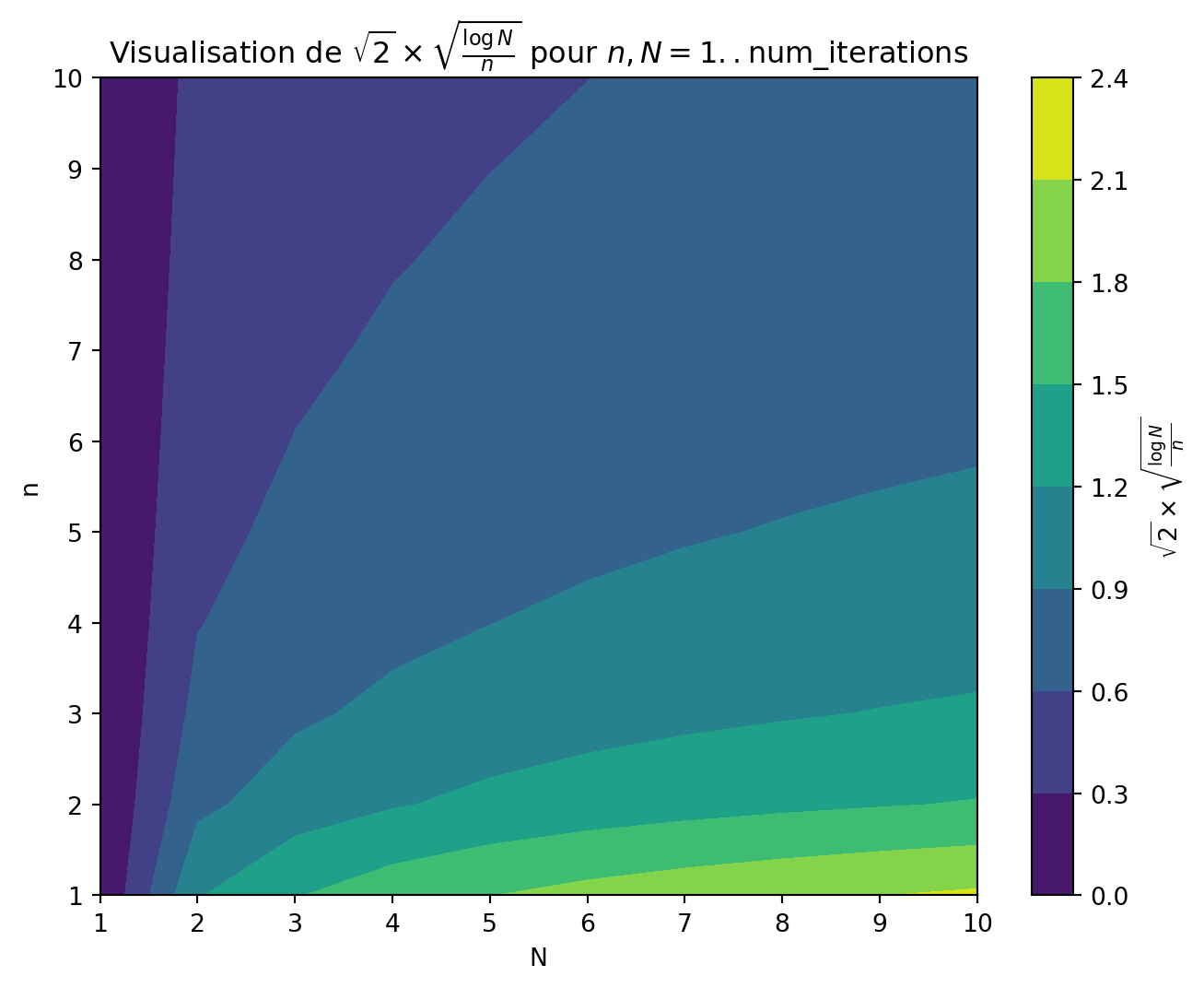
La valeur habituelle pour \(C\) est \(\sqrt{2}\).
L’exploration se produit essentiellement lorsque deux nœuds ont approximativement le même score moyen, alors MCTS favorise les nœuds ayant moins de visites (en divisant par \(n\)).
Pour \(n \lt \ln(N)\), la valeur du rapport est supérieure à 1, tandis que pour \(n \gt \ln(N)\), le rapport devient inférieur à 1.
Il y a donc une petite fraction du temps où l’exploration entre en jeu. Mais même alors, la contribution du rapport est assez modérée, nous prenons la racine carrée de ce rapport, multipliée par \(\sqrt{2} \sim 1.414213562\).
Résumé (5)
[4.60517019 6.90775528 9.21034037]
Résumé (5)
Code
import numpy as npimport matplotlib.pyplot as pltnum_iterations =10# Définir la plage pour n et Nn_values = np.arange(1, num_iterations +1)N_values = np.arange(1, num_iterations +1)# Préparer une grille pour n et NN, n = np.meshgrid(N_values, n_values)# Calculer l'expression pour chaque paire (n, N)Z = np.sqrt(2) * np.sqrt(np.log(N) / n)# Tracéplt.figure(figsize=(8, 6))plt.contourf(N, n, Z, cmap='viridis')plt.colorbar(label=r'$\sqrt{2} \times \sqrt{\frac{\log{N}}{n}}$')plt.xlabel('N')plt.ylabel('n')plt.title(r'Visualisation de $\sqrt{2} \times \sqrt{\frac{\log{N}}{n}}$ pour $n, N = 1..\mathrm{num\_iterations}$')plt.show()
Résumé (5)
Code
import numpy as npimport matplotlib.pyplot as pltnum_iterations =100# Définir la plage pour n et Nn_values = np.arange(1, num_iterations +1)N_values = np.arange(1, num_iterations +1)# Préparer une grille pour n et NN, n = np.meshgrid(N_values, n_values)# Calculer l'expression pour chaque paire (n, N)Z = np.sqrt(2) * np.sqrt(np.log(N) / n)# Tracéplt.figure(figsize=(8, 6))plt.contourf(N, n, Z, cmap='viridis')plt.colorbar(label=r'$\sqrt{2} \times \sqrt{\frac{\log{N}}{n}}$')plt.xlabel('N')plt.ylabel('n')plt.title(r'Visualisation de $\sqrt{2} \times \sqrt{\frac{\log{N}}{n}}$ pour $n, N = 1..\mathrm{num\_iterations}$')plt.show()
Tic-tac-toe
# Classe pour le jeu de Tic-Tac-Toeclass TicTacToe:def__init__(self):# Initialiser le plateau 3x3 avec des espaces videsself.size =3self.board = np.full((self.size, self.size), ' ')def get_valid_moves(self, state):""" Retourne une liste de positions disponibles sur le plateau. """ moves = [(i, j) for i inrange(self.size) for j inrange(self.size) if state[i][j] ==' ']return movesdef make_move(self, state, move, player):""" Place le symbole du joueur sur le plateau à la position spécifiée. Retourne le nouvel état. """ new_state = state.copy() new_state[move[0], move[1]] = playerreturn new_statedef get_opponent(self, player):""" Retourne l'adversaire du joueur donné. """return'O'if player =='X'else'X'def is_terminal(self, state):""" Vérifie si le jeu est terminé, soit par victoire soit par match nul. """returnself.evaluate(state) !=0or' 'notin statedef evaluate(self, state):""" Évalue l'état du plateau. Retourne : 1 si 'X' gagne, -1 si 'O' gagne, 0 sinon (match nul ou jeu en cours). """ lines = []# Lignes et colonnesfor i inrange(self.size): lines.append(state[i, :]) # Ligne i lines.append(state[:, i]) # Colonne i# Diagonales lines.append(np.diag(state)) lines.append(np.diag(np.fliplr(state)))# Vérification d'un gagnantfor line in lines:if np.all(line =='X'):return1elif np.all(line =='O'):return-1# Pas de gagnantreturn0def display(self, state):""" Affiche le plateau dans la console. """print("\nPlateau actuel :")for i inrange(self.size): row ='|'.join(state[i])print(row)if i <self.size -1:print('-'* (self.size *2-1))
Node
# Classe Node pour MCTSclass Node:def__init__(self, state, parent=None, move=None, player='X'):self.state = state # État du jeu à ce nœudself.parent = parent # Nœud parentself.children = [] # Liste des nœuds enfantsself.visits =0# Nombre de fois que le nœud a été visitéself.wins =0# Nombre de victoires à partir de ce nœudself.move = move # Coup qui a mené à ce nœudself.player = player # Joueur qui a effectué le coupdef is_fully_expanded(self, game):""" Vérifie si tous les coups possibles à partir de ce nœud ont été explorés. """returnlen(self.children) ==len(game.get_valid_moves(self.state))def best_child(self, c_param=math.sqrt(2)):""" Sélectionne le nœud enfant avec la valeur UCB1 la plus élevée. """ choices_weights = []for child inself.children:if child.visits ==0: ucb1 =float('inf')else: win_rate = child.wins / child.visits exploration = c_param * math.sqrt((2* math.log(self.visits)) / child.visits) ucb1 = win_rate + exploration choices_weights.append(ucb1)returnself.children[np.argmax(choices_weights)]def most_visited_child(self):""" Sélectionne le nœud enfant avec le plus grand nombre de visites. """ visits = [child.visits for child inself.children]returnself.children[np.argmax(visits)]
mcts
# Algorithme MCTSdef mcts(game, root, iterations):for _ inrange(iterations): node = tree_policy(game, root) reward = default_policy(game, node.state, node.player) backup(node, reward)return root.most_visited_child()def tree_policy(game, node):""" Phases de sélection et d'expansion. """whilenot game.is_terminal(node.state):ifnot node.is_fully_expanded(game):return expand(game, node)else: node = node.best_child()return nodedef expand(game, node):""" Élargir un nœud enfant à partir du nœud actuel. """ tried_moves = [child.move for child in node.children] possible_moves = game.get_valid_moves(node.state)for move in possible_moves:if move notin tried_moves: next_state = game.make_move(node.state, move, node.player) child_node = Node(state=next_state, parent=node, move=move, player=game.get_opponent(node.player)) node.children.append(child_node)return child_nodedef default_policy(game, state, player):""" Phase de simulation : jouer le jeu aléatoirement à partir de l'état donné. """ current_state = state.copy() current_player = playerwhilenot game.is_terminal(current_state): possible_moves = game.get_valid_moves(current_state) move = random.choice(possible_moves) current_state = game.make_move(current_state, move, current_player) current_player = game.get_opponent(current_player) result = game.evaluate(current_state)return resultdef backup(node, reward):""" Phase de rétropropagation : mettre à jour les statistiques du nœud. """while node isnotNone: node.visits +=1# Mettre à jour les victoires. Si le résultat est une victoire pour le joueur qui vient de jouer, ajouter 1.if (node.player =='X'and reward ==1) or (node.player =='O'and reward ==-1): node.wins +=1elif reward ==0: node.wins +=0.5# Considérer un match nul comme une demi-victoire node = node.parent
test_tic_tac_toe_mcts
# Fonction principale pour démontrer l'applicationdef test_tic_tac_toe_mcts(): game = TicTacToe() current_state = game.board.copy() current_player ='X' root_node = Node(state=current_state, player=current_player)whilenot game.is_terminal(current_state): game.display(current_state)print(f"C'est le tour du joueur {current_player}.")if current_player =='X':# Tour de l'IA utilisant MCTS iterations =1000# Ajuster si nécessaire best_child = mcts(game, root_node, iterations) current_state = best_child.state root_node = best_childelse:# Tour du joueur humain possible_moves = game.get_valid_moves(current_state)print("Coups possibles :", possible_moves) move =Nonewhile move notin possible_moves:try: move_input =input("Entrez votre coup sous la forme 'ligne,colonne' : ") move =tuple(int(x.strip()) for x in move_input.split(','))except:print("Entrée invalide. Veuillez entrer les numéros de ligne et de colonne séparés par une virgule.") current_state = game.make_move(current_state, move, current_player)# Mettre à jour l'arbre : trouver ou créer le nœud enfant correspondant au coup matching_child =Nonefor child in root_node.children:if child.move == move: matching_child = childbreakif matching_child: root_node = matching_childelse: root_node = Node(state=current_state, parent=None, move=move, player=game.get_opponent(current_player))# Changer de joueur current_player = game.get_opponent(current_player)# Fin de la partie game.display(current_state) result = game.evaluate(current_state)if result ==1:print("X gagne !")elif result ==-1:print("O gagne !")else:print("C'est un match nul !")if__name__=="__main__": test_tic_tac_toe_mcts()
Exploration
Implémentez un code pour visualiser l’arbre de recherche, soit sous forme de texte, soit en utilisant Graphviz.
Incorporez des heuristiques pour détecter lorsqu’un coup gagnant est réalisable en un seul mouvement.
Expérimentez en faisant varier le nombre d’itérations et la constante \(C\).
Prologue
Résumé
La recherche d’arbre de Monte Carlo (MCTS) est un algorithme de recherche utilisé pour la prise de décision dans des jeux complexes.
MCTS fonctionne en quatre étapes principales : Sélection, Expansion, Déroulement (Simulation) et Rétropropagation.
Il équilibre exploration et exploitation en utilisant la formule UCB1, qui guide la sélection des nœuds en fonction du nombre de visites et des scores.
MCTS maintient un arbre de recherche explicite, mettant à jour les valeurs des nœuds de manière itérative en fonction des simulations.
L’algorithme a des applications variées, y compris dans les jeux d’IA, la conception de médicaments, le routage de circuits et la conduite autonome.
Introduit en 2008, MCTS a gagné en importance grâce à son utilisation dans AlphaGo en 2016.
Contrairement aux algorithmes traditionnels comme \(A^\star\), MCTS utilise des politiques dynamiques et exploite tous les nœuds visités pour la prise de décision.
Mettre en œuvre MCTS implique de suivre les statistiques des nœuds et d’appliquer la formule UCB1 pour guider la recherche.
Un exemple pratique de MCTS est démontré à travers l’implémentation du Tic-Tac-Toe.
Une exploration plus approfondie inclut l’intégration de MCTS avec des modèles d’apprentissage profond comme AlphaZero et MuZero.
Consultez le site web du cours pour obtenir des informations sur l’examen final.
Références
Chaslot, Guillaume, Sander Bakkes, Istvan Szita, et Pieter Spronck. 2008. « Monte-carlo tree search: a new framework for game AI ». In Proceedings of the Fourth AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, 216‑17. AIIDE’08. Stanford, California: AAAI Press.
Kemmerling, Marco, Daniel Lütticke, et Robert H. Schmitt. 2024. « Beyond games: a systematic review of neural Monte Carlo tree search applications ». Applied Intelligence 54 (1): 1020‑46. https://doi.org/10.1007/s10489-023-05240-w.
Russell, Stuart, et Peter Norvig. 2020. Artificial Intelligence: A Modern Approach. 4ᵉ éd. Pearson. http://aima.cs.berkeley.edu/.
Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, et al. 2016. « Mastering the game of Go with deep neural networks and tree search ». Nature 529 (7587): 484‑89. https://doi.org/10.1038/nature16961.